Deep Parametric Continuous Convolutional Neural Networks
- 杂志: CVPR
- IF: None
- 分区: None
Introduction
discrete CNN作为基础的深度学习模块,在效率和表现上都无话可说,但其只适用于dense grid structure。但对于其他结构的的数据,比如3D点云数据、mesh registration、non-rigid shape数据,discrete CNN无法处理。
对于这些数据的解决方法有:
- Voxelize the space to form a grid,然后使用discrete CNN【29,24】,但这样会导致tensor中大多数元素都是0,从而浪费内存。
- Geometric deep learning【3,15】和GNN【25,16】使用处理graph的方式来处理这些这些数据,但这样的处理方法有两个缺陷:
- 难以推广;
- 需要极好的feature representations才能表现不错;
本文提出一种新的思路,称为parametric continuous convolution。思想是使用一个参数化的核函数,来spans整个连续向量空间。
- 这种新的神经网络架构可以很自然地适用于在空间内分布不均的3D点云数据。
- 在semantic labeling和motion estimation任务上验证了continuous CNN的有效性,使用end-to-end的网络架构。
- 证明了本方法在very large scale dataset上的有效性(223 billion points)。
相关研究
Deep Learning for 3D Geometry:
最好的方法是将3D数据变成2-d RGB的image,然后使用传统的CNN进行学习【17,10】,但这不能捕捉到真实的几何关系,相邻的像素点可能相距很远的。
我猜测,是将3D的一个维度转换成image的channel
另一种方式是使用3d CNN,但需要将数据变成volumetric representations【29,21,24,9,18】:
- 其中将数据填补成3d grid结构的过程,称为voxelization。
- 这在medical imaging、indoor scene understanding中应用好比较多,因为volume比较小。
但此方法的问题在于:
- 典型的voxelization牺牲了精确度。
- 3d volumetric representations是非常耗内存的。
进一步的改进是使用sparse CNN【9】或新的数据结果(oct-trees【24】)
最新的想法是PointNet【20】和PointNet++【22】,其直接使用MLP来学习单个点,然后使用pooling来总结global information。
Graph Neural Networks:
GNN的早期应用主要在于进行node representation的学习,【23】使用GGNNs进行point cloud segmentation,得到了state-of-the-art。
但GNN模型的问题在于,其图中节点信息的传播是同步的,这样对于millions节点的图,就因为图太大无法实现。
Graph Convolution Networks:
- 对于spectral methods【4,2,30】,GCN方法,问题是无法扩展到large scale的data。
- spatial approachs【6,15,7,19,2,27,30,26】则要灵活一些,本文的方法可以看做是spatial GCN的推广。
Other Approaches:
- Edge-conditioned filter networks【27】使用参数化的network来联系graph中的邻接点,相对于它,本文的方法不需要限制在fixed graph structure上。
- 【26】使用了本文方法类似的结构,但其使用的是shallow isotropic gaussian kernels,但本文使用的是更加expressive deep networks。
Methods
1. Parametric Continuous Convolutions
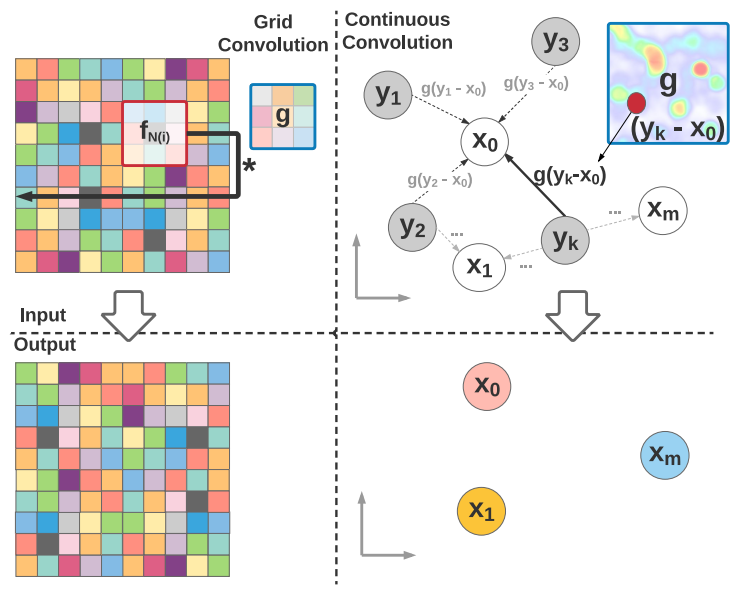
传统的discrete CNN有如下的运算:
\[h[n]=(f * g)[n]=\sum_{m=-M}^{M} f[n-m] g[m]\]
其中\(f: \mathcal{G} \rightarrow \mathbb{R}\)、\(g: \mathcal{S} \rightarrow \mathbb{R}\),其中\(\mathcal{G}=\mathcal{Z}^{D}\)、\(\mathcal{S}=\{-M,-M+1, \ldots, M-1, M\}^{D}\)。
这个公式确实是discrete CNN,其中g是kernel,f[n-m]就是以n为中心,两边半径为m的邻域。
continuous CNN的形式应该是:
\[h(\mathbf{x})=(f * g)(\mathbf{x})=\int_{-\infty}^{\infty} f(\mathbf{y}) g(\mathbf{x}-\mathbf{y}) d \mathbf{y}\]
其中\(\mathcal{G}=\mathbb{R}^{D}\) and \(\mathcal{S}=\mathbb{R}^{D}\)。
这个形式有两个问题需要解决:
- 显然积分是无法计算的。
- 卷积核\(g\)是什么
受到monte-carlo积分【5】的启发,可以得到下面的形式:
\[h(\mathbf{x})=\int_{-\infty}^{\infty} f(\mathbf{y}) g(\mathbf{x}-\mathbf{y}) d \mathbf{y} \approx \sum_{i}^{N} \frac{1}{N} f\left(\mathbf{y}_{i}\right) g\left(\mathbf{x}-\mathbf{y}_{i}\right) \tag{1}\]
这样就解决了积分的问题
至于\(g\)(卷积核)的形式,在discrete CNN中,是为每个离散的位置都赋予一个单独的参数,但这不可能在continuous上实现。
解决方案也是简单的,直接使用一个MLP来实现
根据universal approximation theorem【12】,MLPs有足够的能力来拟合\(\mathbb{R}^n\)上的任意连续函数。
即:
\[g(\mathbf{z} ; \theta)=M L P(\mathbf{z} ; \theta)\]
实际上多项式也是可以的,但问题在于low-order的多项式没有足够的能力,而high-order的多项式数值计算不稳定
注意到continuous CNN有个特点:其输入的点的位置可以和输出的点的位置不一样,这是因为式1中的\(y\)是可以取任意的连续值的。这实际上隐式的提供了一种pooling的方式。
2. 构建Deep Networks
continuous CNN的输入有3个部分:
- 输入特征:\(\mathcal{F}=\left\{\mathbf{f}_{\mathrm{in}, j} \in \mathbb{R}^{F}\right\}\);
- 相应的位置坐标:\(\mathcal{S}=\left\{\mathbf{y}_{j}\right\}\);
- 输出的位置坐标:\(\mathcal{O}=\left\{\mathbf{x}_{i}\right\}\);
所以每一层的计算公式为:
\[h_{k, i}=\sum_{d}^{F} \sum_{j}^{N} g_{d, k}\left(\mathbf{y}_{j}-\mathbf{x}_{i}\right) f_{d, j}\]
其中\(N\)是输入点的个数,\(i\)是输出点的index,\(d\)是位置信息的维度index,\(k\)是kernel的index。
显然,可以类似discrete CNN那样来搭建Continuous CNN的block,比如加入BN、非线性激活等等。注意,residual connection是非常必要的,因为可以帮助快速收敛。
下图是一个block的搭建:
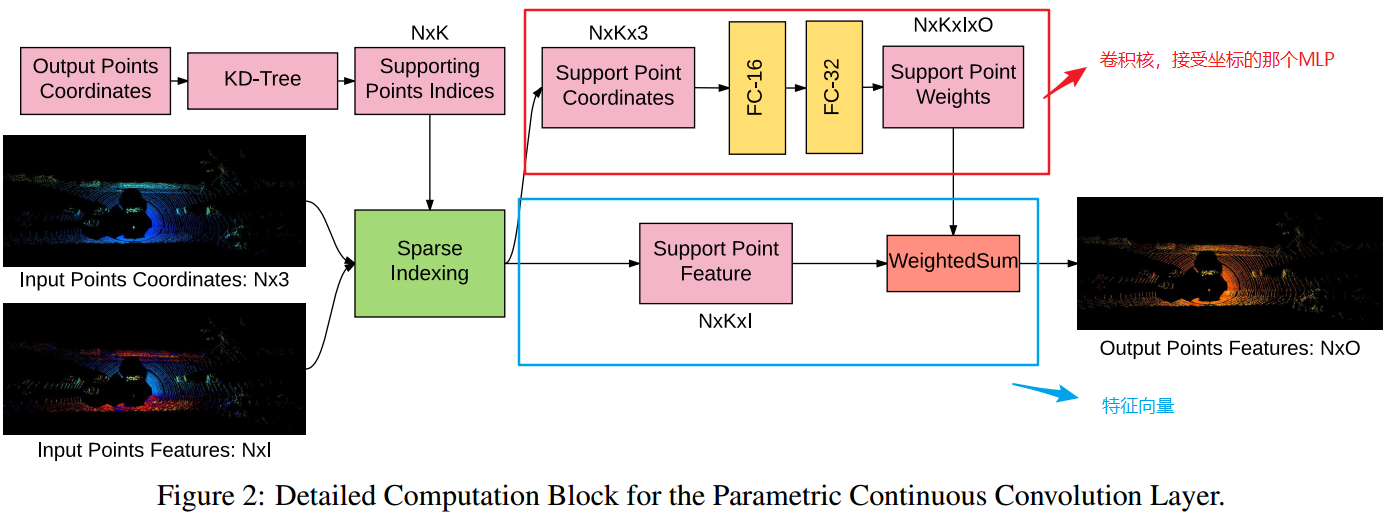
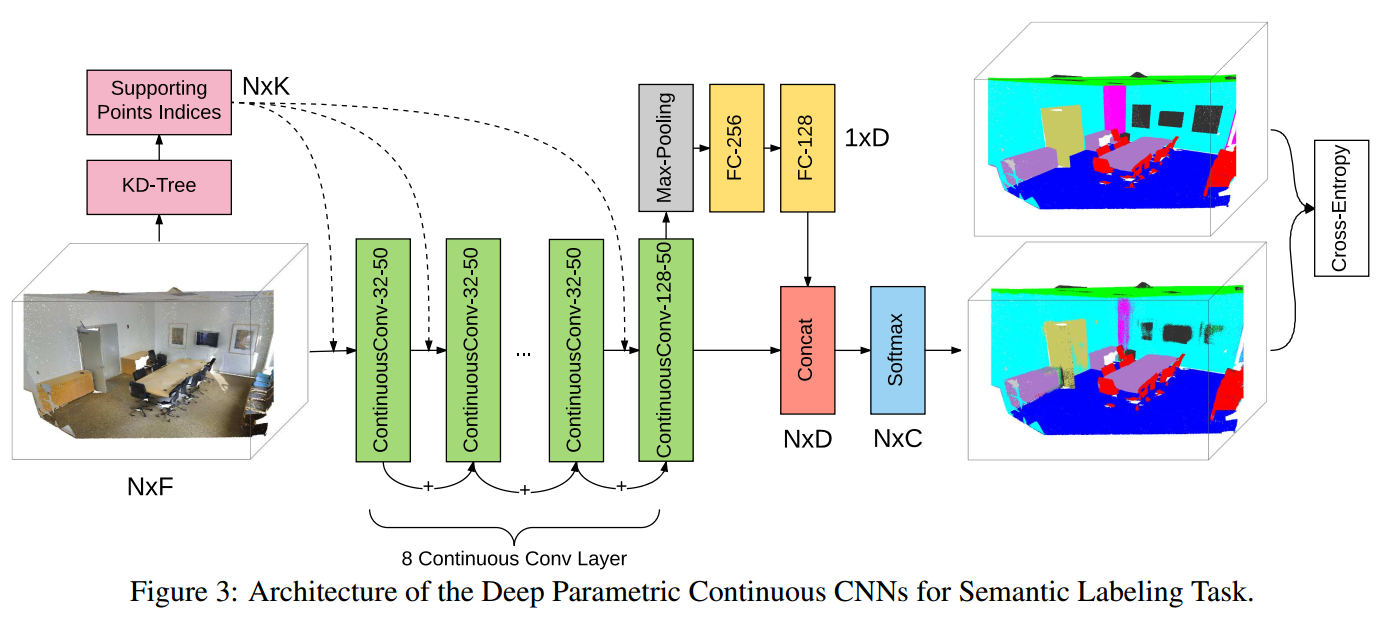
下图是本文进行实验时整个网络的结构:
3. 讨论
locality enforcing continuous convolution:
传统的discrete CNN因为kernel是有限大小的,所以能够有局部性(locality),而continuous CNN也可以通过一些操作来具有局部性:
\[g(\mathbf{z})=M L P(\mathbf{z}) w(\mathbf{z})\]
有两种思路来实现:
- \(w(\mathbf{z})\)是一个characteristic function,对应的set是对应点的knn,其中邻居的数量假设为\(|\mathbf{S}|\),称为cardinality of the support domain。
- \(w(\mathbf{z})\)是一个characteristic function,对应的set是对应点为圆心形成的半径固定的邻域。
efficient continuous convolution:
在每一层conv layer中,kernel function(MLP)的执行次数是\(N\times |\mathbf{S}|\times F\times O\),其中\(N\)是点的数量、\(|\mathbf{S}|\)是cardinality of the support domain的大小,\(F\)和\(O\)分别表示输入和输出的特征的维度。运算和内存是非常expensive的,因为我们需要储存一个以上维度的weighted matrix(由MLPs计算得到的),来和features进行weighted sum。
首先我们分析一下discrete CNN的一层layer中的kernel tensor的维度,是一个4d tensor。首先是kernel本身的size(\(h,w\)),然后是输入的channel,这3个维度聚合只能得到一张feature map,为了能够提取更多的信息,就需要设置多个kernels,每个kernel形成一张2d的feature map,多张2d feature map形成一个新的有channel的“图片“。所以就有了第4个维度,其大小等于输出的channel的大小。
另外,我们需要对每个点都进行一次以此点为中心的weighted sum操作。假设我们针对的图片是\(H\times W\)大小的,对于这样的一张图片(一个样本),一共做了乘法的次数是\(hw\times i\times o\times HW\)。
continuous CNN是类似的。上面的公式中,\(N\)相等于\(HW\),\(|\mathbf{S}|\)相当于\(hw\),\(F\)相当于\(i\),\(O\)相等于\(o\)。为了能够提高效率,方法是将上面那个我们需要MLP生成的\(N\times |\mathbf{S}|\times F\times O\)维度tensor,拆分成两个tensor的叉乘:
\[ \begin{aligned} W_{N\times |\mathbf{S}|\times F\times O} &= W_1 \times W_2 \\ &=W_{F\times O} \times W_{N\times|\mathbf{S}|\times O} \end{aligned} \] 其中\(W_2\)是通过MLP生成的(MLP输出维度是\(O\),运行\(N\times|\mathbf{S}|\)次),\(W_1\)是一个单独的参数矩阵。
这相当于认为input channels进行了一定的参数共享,使用线性空间的角度来看:input channels间的参数是有一个相同的基向量(\(W_1\))生成的空间,坐标是MLP的输出。
配合BN,可以提高执行效率3倍,而且降低了内存占用。
special cases:
实际上上面介绍的是continuous CNN框架的一种特殊情况而已,continuous CNN框架是非常general的。比如其可以通过特殊的设计,变成gaussian kernel、first-order spatial graph convolution【15】等。
Results
以下的结果来自点云分割任务,而对于此任务,我不是非常了解,所以可能会有一些错误的理解。我进行只进行结果的简单记录,目的是对continuous CNN的性能有一个初步的印象。
基于3D点云的实验任务有两个:
- Semantic labeling
- outdoor lidar(激光雷达)semantic segmentation dataset,137 billion points
- indoor semantic labeling dataset,629 million points【1】
- motion estimation
1. Semantic Segmentation of Indoor Scenes
train和test流程来自【28】,输入是6个维度(x、y、z、r、g、b),类别数是13类。
比较算法:PointNet【20】和SegCloud【28】
参数设置:一共有8个continuous CNNs,前7个的channels是32,最后一个是128,然后将最后一层的数据在所有点上进行global pooling,然后将这个feature concat到每个点的特征上,得到256的特征,然后为每一个点使用一个fc-softmax进行分类。loss是cross entropy loss,optimizer是Adam。
结果:下面的图和表分别显示了指标的结果和分类的质量:

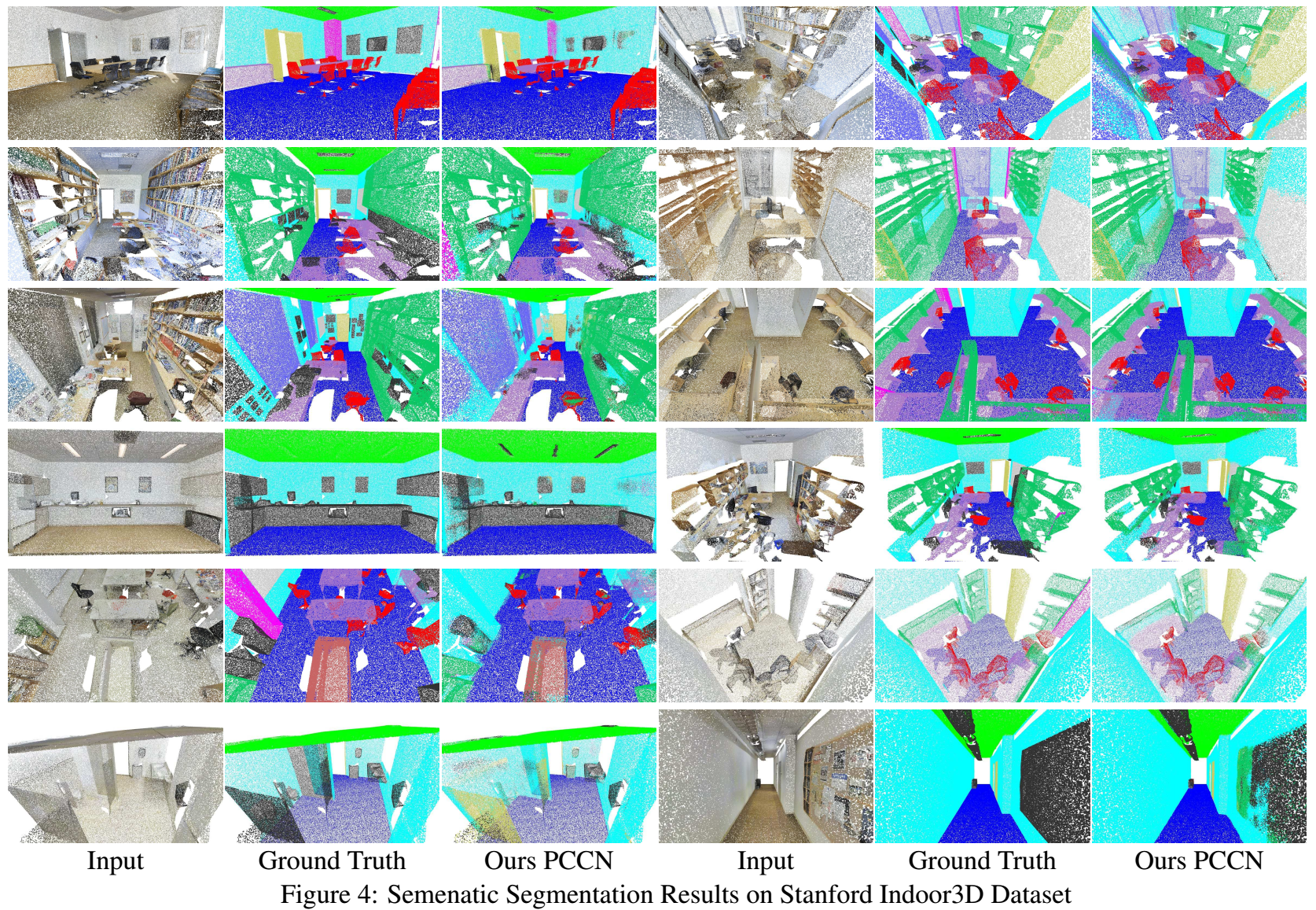
结果显示,PCCN效果还是非常好的。
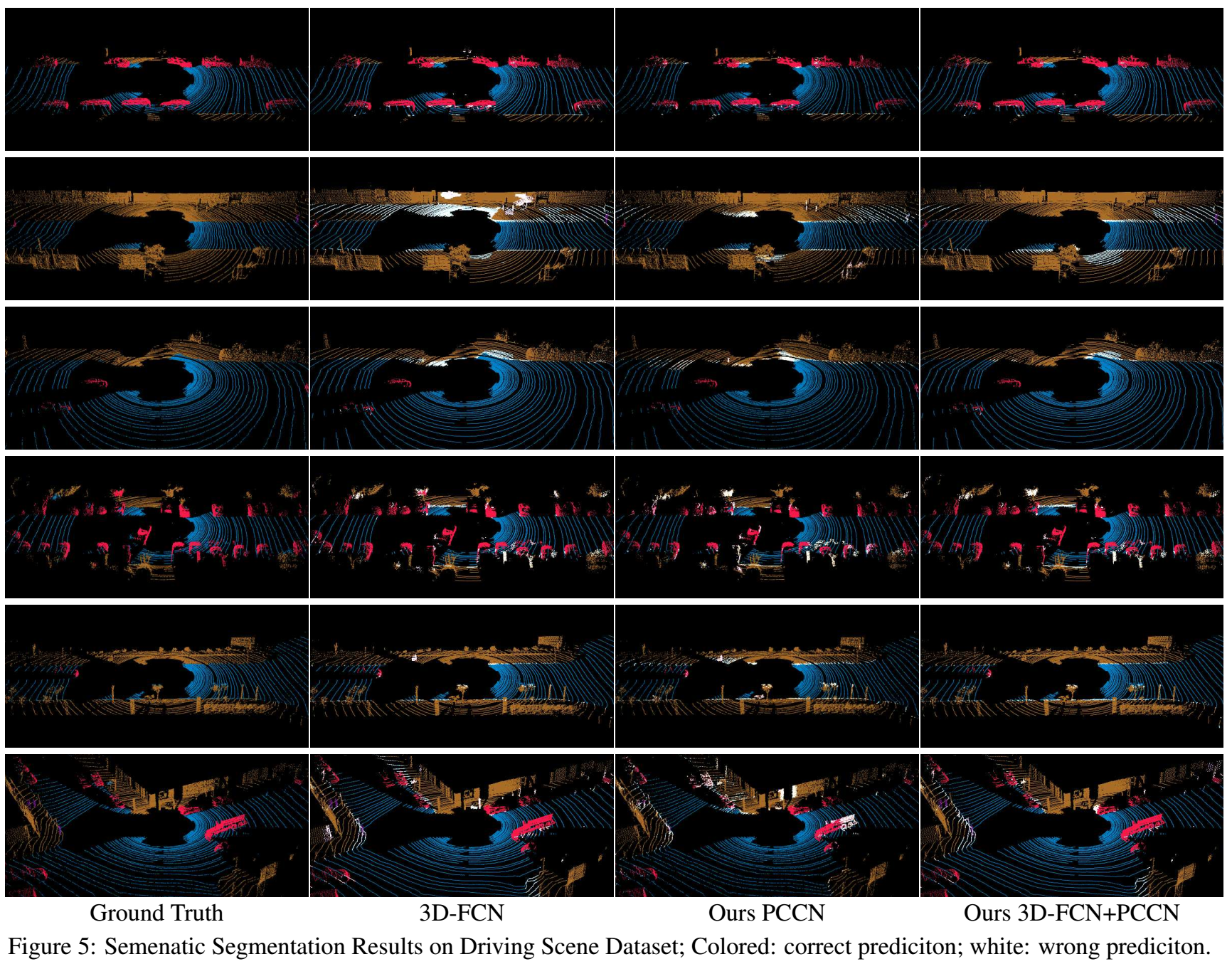
2. Semantic Segmentation of Driving Scenes
该数据集由snippets组成,每个snippets有300 frames(帧):
- training and validation set 11337 snippets
- test set 1644 snippets,每个snippets随机采样10个frames用来避免一些静态场景(等待红绿灯)所带来的影响
类别数是7类,指标是meanIOU和pointACC。
比较算法:
- PointNet【20】,移除了point rotation layer
- 3D-FCN,ResNet-50作为backbone并将最后的pooling和fc替换为FC layers和trilinear upsampling layer来进行分割,loss是class-reweighted cross-entropy loss,adam optimizer
参数设置:使用了两个版本
- 直接输入xyz lidar points(PCCN),16个continuous CNNs,有residual connections、BN和ReLU,pointwise cross-entropy loss,adam optimizer
- 3D-FCN+PCCN,即前面先使用3D-FCN进行特征的预处理,然后连接7个continuous CNNs,设置和上面相同
结果:

我们可以看到,PCCN模型的参数量也是非常小的。
运行速度:
使用GTX 1080Ti和Xeon E5-2687W CPU、32G内存,8-layers PCNN的forward pass是33ms、KD-Treeneighbour search是28ms,整体的end-to-end的计算是61ms,每一层的计算量是1.32 GFLOPs。
1 GFLOPs大约是\(10^9\)次运算。
3. Lidar Flow
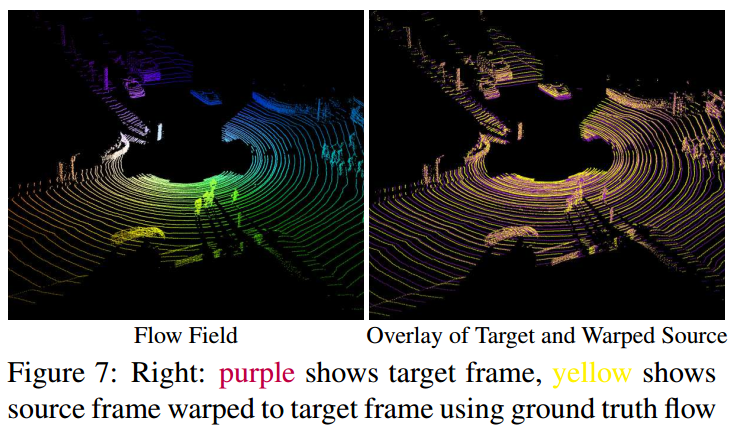
training set和validation set有11337 snippets(110k frame pairs),test set有1644 snippets(16440 frame pairs)。
比较算法:3D-FCN
参数设置:移除了ReLU、使用MSE loss
结果:
如下面的表格和图片所示:


Conclusion
提出了一种新的深度学习框架,可以应用于non-grid的data。并在点云分割和运动估计中验证了该方法的有效性。
Questions
其实思想是非常简单的,但在点云分割中竟然能够work而且效果这么好是令我惊讶的。更令我惊讶的是其在GTX 1080Ti上还能够有比较快的速度。



