PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation
- 杂志: CVPR
- IF: None
- 分区: None
- github(我的实现)
Introduction
CNN需要输入regular data formats才能完成权重共享等性质,而point clouds等数据格式并不满足。通常的做法是将其转换成3D voxel grids或不同视角的images,这会使得数据量急剧增加而且带来一些没有必要的变异性。
本研究提出一种新的框架--PointNet,
- 将point cloud data看做真正的点集,即保持了其中成员的排列不变性(invariant to permutations)、刚性运动不变性(invariant to rigid motions)等。
- unified architecture,end-to-end,直接将point clouds作为输入(xyz坐标),输出为整个point cloud的label或每个point的label。
- 结构简单,关键在于使用了一个single symmetric function —— max pooling。首先将每个点映射为各自的features,然后再进行summaries或concat上其他的global features。
- 因为输入的时候,对于每个point是独立的,所以可以进行一定的数据预处理,比如进行空间的缩放变化来让数据更加规范,从而提高训练的效果。
本研究还对该框架进行了理论上的分析。显示了该networks可以拟合points set上的任意连续函数,而且还提供了一定的可解释性(可视化、为什么PointNet可以对输入点的扰动鲁邦)。
在一系列的benchmark datasets上展示了PointNet有最好的效果。
相关工作
点云特征:
当前大多数的point cloud features是根据任务手动提取的。一般来说需要满足一定的统计特性,而且并分为内在的特征【2,21,3】和外在的特征【18,17,13,10,5】、local和global features。一般来说,如何组合这些features来对特定任务实现最优,这是很难的。
在3D数据上的深度学习
- Volumetric CNNs:【25,15,16】。但其存在一些问题:数据稀疏性(FPNN【12】和Vote3D【23】),计算复杂性。
- CNNs:【20,16】,并在shape classification和retrieval tasks上得到了非常好的效果。但这并不能推广到所有的3D data上,特别是point classification或shape completion。
- Spectral CNNs:【4,14】。
- Feature-based DNNs:【6,8】,先提特征再使用fc layers进行分类,这可能会受限于其提取特征的能力。
在非排序集合上的深度学习
【22】使用了一个带有注意力机制的read-process-write network来解决这个问题,并证明了其有排序数字的能力。但这个工作是在NLP上的,所以其没有考虑到sets上的几何关系。
Methods
1. 问题
数据集为3D点集:\(\{P_i|i=1,\ldots,n\}\),其中每个point是它的坐标\((x,y,z)\)和其他的特征向量。本研究中只有其坐标。
- 对于object classification task,其输入一个已经分割好的、有形状的点云,然后进行分类与预测。
- 对于semantic segmentation,则输入一块区域的点云,然后为每个点预测其分类。
数据特征:
- unordered。所以这个点云如果有\(N\)个点,则这\(N\)个点的permutation都是一样的。
- interaction among points。能够捕捉点间的local structures,计算local structures内的interactions。
- invariance under transformations。比如旋转、平移points并不会影响结果。
2. PointNet结果
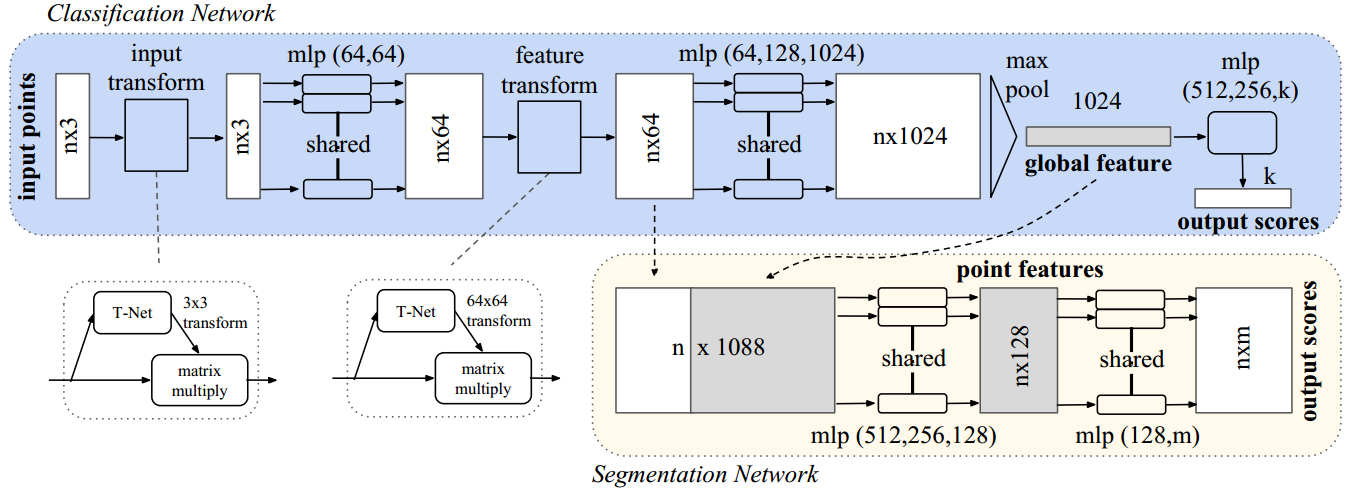
以上的结构中有3个关键模块:
- max pooling layers,symmetric operation,用来得到global features
- local and global features的combination structure
- two join alignment network将输入和输出对齐
2.1 对称函数
为了保证model有invariant to input permutation,有以下3种策略:
每次输入时都将输入排列成一个排法。
但实际上在高维空间中并不存在一个对点扰动稳定的排列。在高维空间中,只要有小小的扰动,则其排列就可能发生了较大的变化。
将输入的所有排列都输入训练一次。
如果使用RNN,其对于比较长的点集序列是很难学习到的,而且permutation得到的数据量太大了。后面也用实验证明了基于此策略的RNN效果是不如PointNet的。
使用一个symmetric function来提取信息,symmetric function在不同的排列下降输出相同的值。
这是本研究的策略。整个模型可以表示为下面的格式:
\[f(\{x_1,\ldots,x_n\})\approx g(h(x_1),\ldots,h(x_n))\]
在本文中,\(h(x)\)就是一个mlp,\(g()\)就是一个max pooling。结构简单,但效果很好。
2.2 局部和全局信息融合
这在semantic segmentation任务上是需要的。解决方案也是简单的,就是将pooling后的特征重新和每个点的特征进行concat,然后重新为每个点提取特征。
2.3 联合对齐网络
point cloud在经过一些刚性变换后应该是不变的,若学习到的representation应该是保留这种不变性的。
解决策略是:point cloud在进入model前先进行一个变换,使得其先变成标准的形状。则对于不同的样本,可能需要不同的变换。
本研究的思想是简单的,直接设计一个mini-network,其输入point cloud,输出一个\(3\times 3\)矩阵,这个矩阵代表的就是适用于这个样本的变换。这个mini-network(T-net)的结构和上面是一致的。
进一步,我们可以为feature space也应用这样的结构,来对其feature space。因为feature space拥有较高的维度,为了防止得到的变换矩阵会降低输出后的秩(损失信息),所以需要在loss上加入一定的regularization:
\[L_{reg}=||I-AA^T||^2_F\]
其中\(A\)是变换矩阵。这个regularization使得变换矩阵尽量靠近一个正交矩阵,从而避免信息的丢失。
3. 理论分析
通用逼近性(universal approximation)


其中Hausdorff distance的定义wiki:
\[d_H(X,Y)=\max\{\sup\limits_{x\in X}{\inf\limits_{y\in Y}{d(x,y)}},\sup\limits_{y\in Y}{\inf\limits_{x\in X}{d(x,y)}}\}\] 就是
- 先为每个\(x\)点找到\(Y\)上的对应点,这个对应点就是在\(Y\)上和\(x\)距离最近的点。然后计算\(x\)到对应点间的距离。
- 计算这个对应距离的最大值。
- 反过来再算一遍,然后取两个距离的最大值。
证明在附录中。
瓶颈层的维度和稳定性
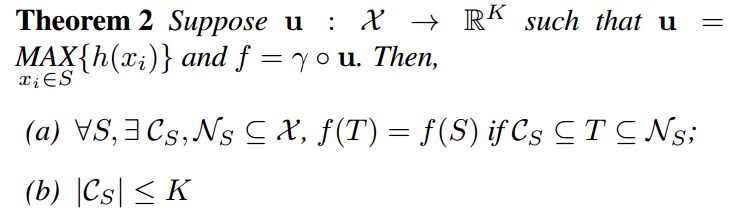
- a的意思是,只要\(\mathcal{C}_S\)中的点保留了,那么去掉一些其他的点,并不会改变函数的输出;同样的,可以加一些额外的噪声点,但只要不超过\(\mathcal{N}_S\),则也不会改变函数的输出。
- b的意思是,作为"关键点"存在的\(\mathcal{C}_S\),其中点的数量被max pooling后得到的特征的维度控制。
称\(\mathcal{C}_S\)为\(S\)的critical point,称\(K\)是\(f\)的bottleneck dimension。
其实这个结果细想一下也是合理的。因为使用的max pooling,所以一些点的信息是被舍弃的,那么只要保证增加或减少的扰动只会影响到这些舍弃的点,则函数的值就不会变。
上面的两个理论分析告诉我们,PointNets通过发现point cloud中的一组稀疏的关键点来工作,这保证了结果的robustness。后面会发现,这组关键点构成了对象的骨架。
Results
1. 应用
3D对象分类
- 数据集:ModelNet40【25】,40类,12311个CAD models(9843 for train,2468 for testing)
- 训练时从每个model随机抽取1024个点进行训练,并进行了单位圆标准化。
- 使用的数据增强:然后绕up-axis进行旋转。每个点的坐标增加了\(\mathcal{N}(0, 0.02^2)\)的噪声。
- baseline使用提取的传统特征+MLP。
结果:
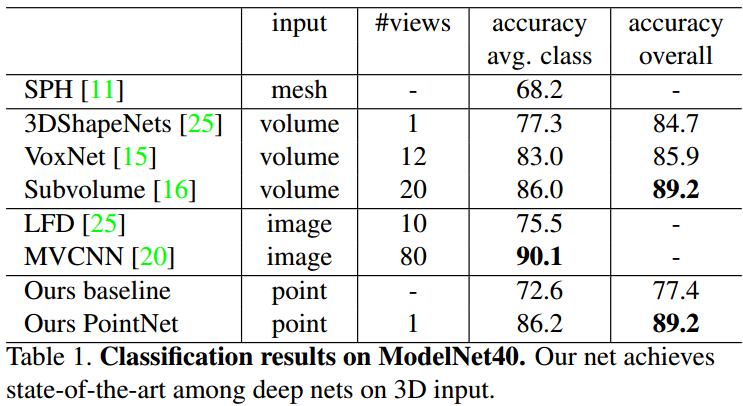
MVCNN的效果略好的原因可能是:图像进行渲染的时候会增加一些细节,这些在点云中没有被保留。
3D对象部分分割
- 数据集:ShapeNet part data set【26】,16881 shapes被分为16类,一共被标记了50个parts。
- 评价指标:mIoU。
- 比较方法:【24】和【26】。
结果:
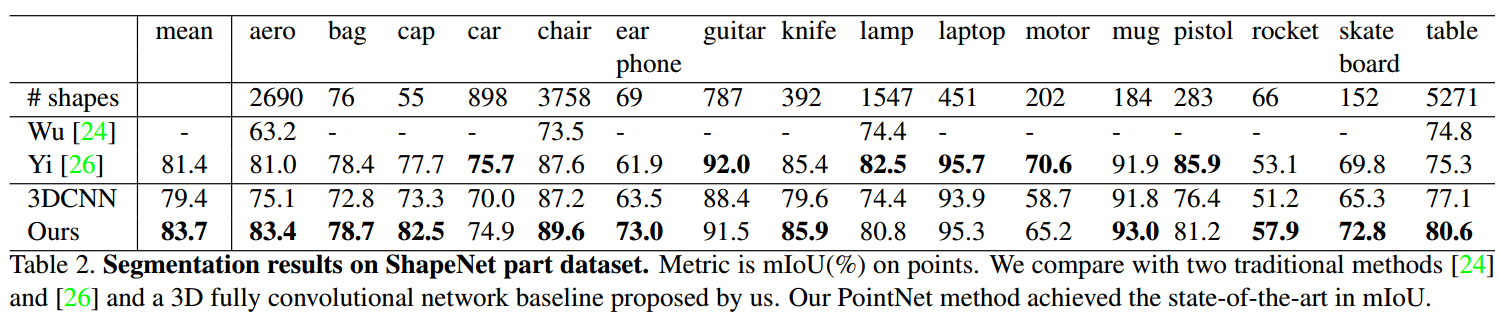
另外,使用Blensor Kinect Simulator【7】来从6个视角生成不正确的点集,然后进行训练,发现PointNets只损失了5.3%的mIoU。

场景语义分割
- 数据集:Stanford 3D semantic parsing data【1】,一共271个rooms。从这些rooms的1x1m的区域内随机取点得到一个point cloud(4096个点for train,all for test)。每个点是一个9-d的向量,即xyz、rgb和normalized location as to room。
- 评价,使用【1】的k-fold策略进行评价。
- baseline:使用的特征除了上面说到的9个,还有local point density、local curvature(曲率)and normal,然后使用MLP进行分类。
结果如下表和图所示:
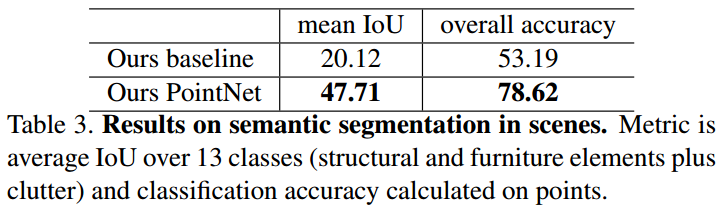

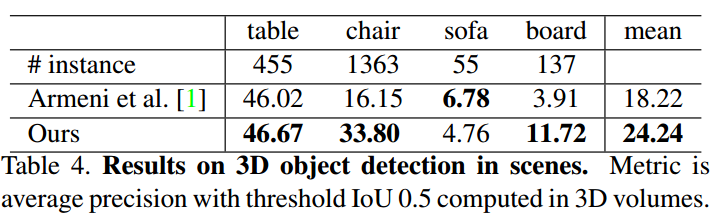
基于上述的语义分割网络,本研究建议了一个3d对象检测系统,并和之前的state-ot-the-art方法进行了比较,结果如下表所示:
2. 架构设计
这里对PointNets中设计的一些架构的作用进行验证。
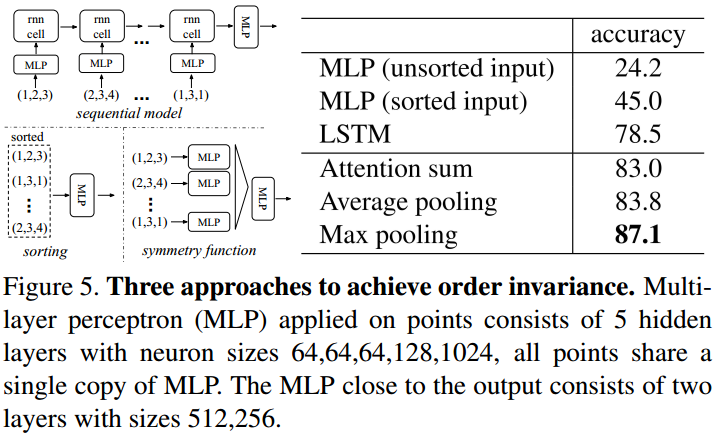
order-invariant方法
使用的数据集是ModelNet40,除了上面提到的方法,还测试不同的symmetric function的效果,其中attention的做法类似【22】,结果如下:
输入输出转换
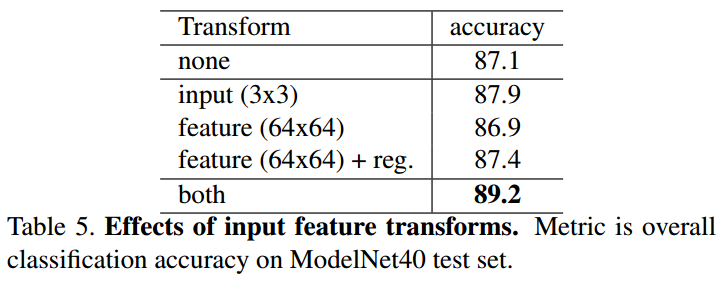
没有T-Net的时候就已经有不错的效果了,将T-Net、regularization都加上后能够得到最好的效果。
鲁棒性测试

当丢失50%的points时,acc仅仅降低了2.4%(furthest sampling)和3.8%(random sampling)。
当outliers占据20%的点的时候,acc也能够到达80%以上。
3. 可视化
这里将\(\mathcal{C}_S\)和\(\mathcal{N}_S\)可视化了一下:

两者可以理解为,PointNet可以理解物体所需要的最少和最多的点的集合。
4. 时间和空间复杂度
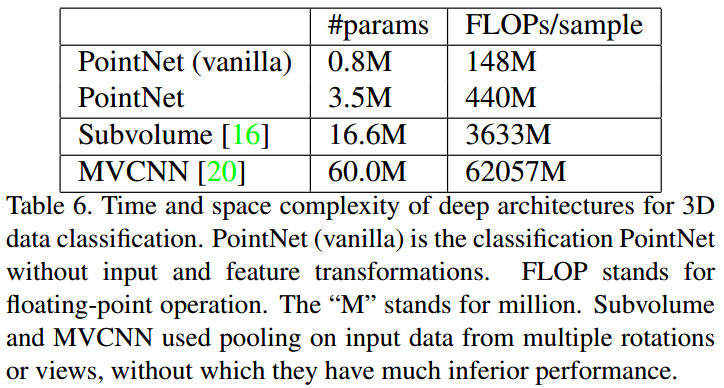
上表总结了其空间和时间花费。在tensorflow上(1080X GPU),PointNet可以每秒处理超过100万个点。



