PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space
杂志: NIPS2017
IF: None
分区: None
-
作者提供的源码是tensorflow的,包括它的实现,为了提高速度,使用了一些C++代码。这里提供的代码是纯正pytorch的,更加利于学习,但可以效率低一些。
Introduction
之前PointNet算是在DL领域对point sets的一个探索,其基本思想是先学习每个点的encoding,然后将所有点的信息进行融合得到global point cloud signature。
但这样的设计使得模型无法捕捉到点云的局部结构,而在CNN的实践中我们知道这是非常重要的,低级别的特征有较小的感受野,高级别的特征有较大的感受野。
所以本研究介绍一个分层的NN框架——PointNet++,
思想是:
- 先将点集分割成可重叠的local regions,通过某些距离度量;
- 类似CNN,从这些local regions中提取特征;
- 将这些特征组合成新的点集,然后继续学习更高级别的特征。
这样,PointNet++的实现面临两个问题:
怎样进行分割?
在欧式空间中,使用最远点采样(FPS)选择centroids,然后使用centroids为中心的球形邻域作为一个local regions。
如何提取点集或local regions的特征?
使用PointNet。
实验显示PointNet++能够有效地、稳健地学习点集的特征,结构也显著优于state-of-the-art。
Methods
\((M, d)\)是一个metric space,其中\(M\in \mathbb{R}^n\)是n维欧式空间的一个子集,\(d\)是其上的一个metric。使用\(\mathcal{X}\)来表示将\(M\)的位置信息、点特征组合在一起的特征点集,则我们的任务是学习一个\(f\)能够得到\(\mathcal{X}\)的富含语义的表示,用于分类或分割。
1. PointNet Review
详见
2. 分层点集特征提取
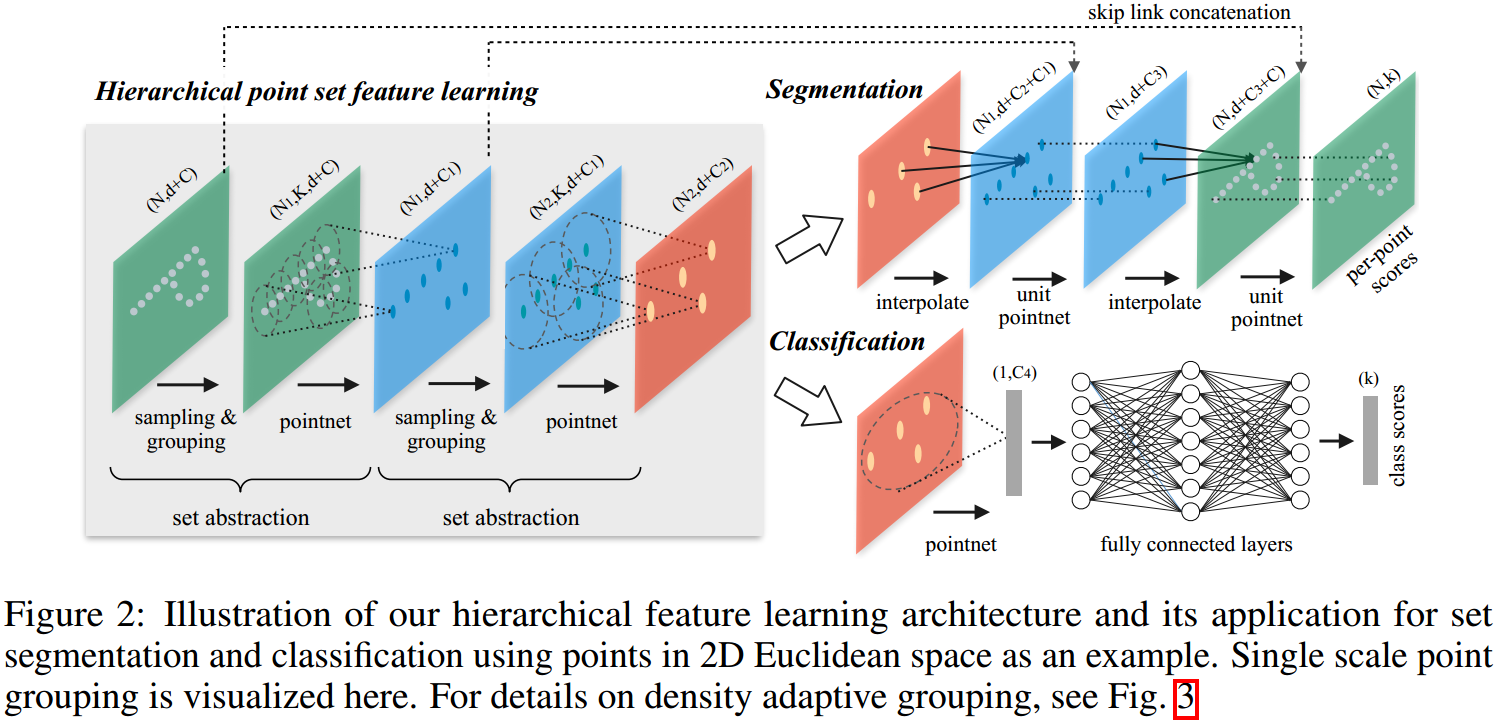
如图所示,整个网络有多个set abstraction layer组成,其将输入的点集(\(N\)个点,每个点的坐标数量\(d\)、特征数量\(C\))进行一系列操作,生成一个有着更少的点、每个点特征更新了的新的点集(\(N'\)个点,每个点坐标数量\(d\)、特征数量\(C'\)),其包含以下3个部分:
Sampling layer
从输入点集中选择一部分点,作为centroids。
方法:使用FPS采集指定数量的centroids,FPS使用到了数据的坐标信息来进行采样,这使得其相比于完全随机采样有更好的覆盖率。
Grouping layer
以centroids为中心,选择其neighborhoods构成local region sets。
方法:使用ball query的方法,即找到在以centroid为中心、一定距离为半径的ball中的所有点作为local region sets,这样每个region sets中的点的数量可能不一样。
相对应的还有一种方案,即kNN,即寻找距离centroid最近的k个点。ball query的方法相对于它,产生的local region features在空间上更加有意义,这对于分割任务可能是有益的。
PointNet layer
使用一个mini-PointNet将local region sets编码成feature vectors。
方法:对于每个local region set,先以centoid为原点转换点集的点的坐标,然后使用PointNet进行学习,在一个PointNet layer中,所有的local region sets使用的PointNet是权值共享的。
3. 非均匀的点云密度
现在有一个问题:很多时候点云并不是均匀分布在空间中的,这种非均匀的分布会导致我们的feature leanring不稳定,在稀疏点集上学习到的特征并不能推广到密集的点集,反之亦然。
为了解决这个问题,本研究提出了一个density adaptive PointNet layer来提到上面的PointNet,此时组合成的整个网络称为PointNet++。
其基本思想是,在每个set abstraction layer中,会进行多个尺度的grouping和PointNet特征提取,然后将这多个尺度的特征根据其points density进行组合,有以下2种方式:
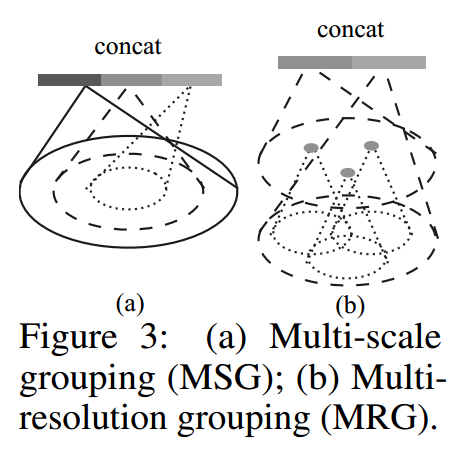
Multi-scale Groupiing(MSG)
如上图a所示,最简单的,即进行多个尺度的grouping和PointNet,然后将特征concat在一起即可。
random input dropout:为每一个样本(点云)随机一个\(\theta\sim \mathcal{U}(0, p)\),然后\(\theta\)为丢弃率将输入的点丢掉。这样,网络会接收到不同程度的输入稀疏性,从而面对非均匀点集也是稳健的。
使用\(p=0.95\)而不是\(1\)是为了防止出现空集合的现象。
以上的操作是面对local region sets做的。Multi-resolution Grouping(MRG)
MSG运行起来效率非常低,因为其需要为每个local sets都执行,而local sets的数量在底层时通常非常大。
MRG的思想是将提取两个层次的特征,然后将其concat到一起。如果点的密度较大,则右边的特征提供了更加细粒度的描述;如果点的密度较小,则左边的特征提取的信息较比较少,主要由右边来负责。
4. 点特征传播
前面的set abstraction layer将点集的信息进行了聚合,但如果我们要进行分割任务,则必须得到每个点的特征。
这里使用差值方法将前面的set abstraction layers逐层反转(见fig2),我们在进行set abstraction的时候就把input points的坐标记录,然后在此处使用插值法、利用较少的output points来把input points得到。
使用的插值法是inverse distance weighted average based on kNN:
\[f^{(j)}(x)=\frac{\sum_{i=1}^k{w_i(x)f_i(x)}}{\sum_{i=1}^k{w_i(x)}} \quad \text{where}\quad w_i(x)=\frac{1}{d(x, x_i)^p},j=1,\cdots,C\]
其中\(p=2, k=3\)。在经过了插值后,再将每个点的特征过一次fc和relu,之后和对应的set abstraction layers的输入concat的一起,然后继续。
Results
使用的数据集有:
- MINST
- ModelNet40
- SHREC15:使用5-CV来进行研究
- ScanNet:1201来train、312来test
classification的evaluation使用acc,semantic scene labeling的evaluation使用average voxel classification acc。
1. 在欧式空间中的分类效果
使用MNIST和ModelNet40来进行评价,训练时分别从中采样512和1024个点,所有点zero mean和unit ball normalization,使用的网络是3层set abstraction layer和3层fc。
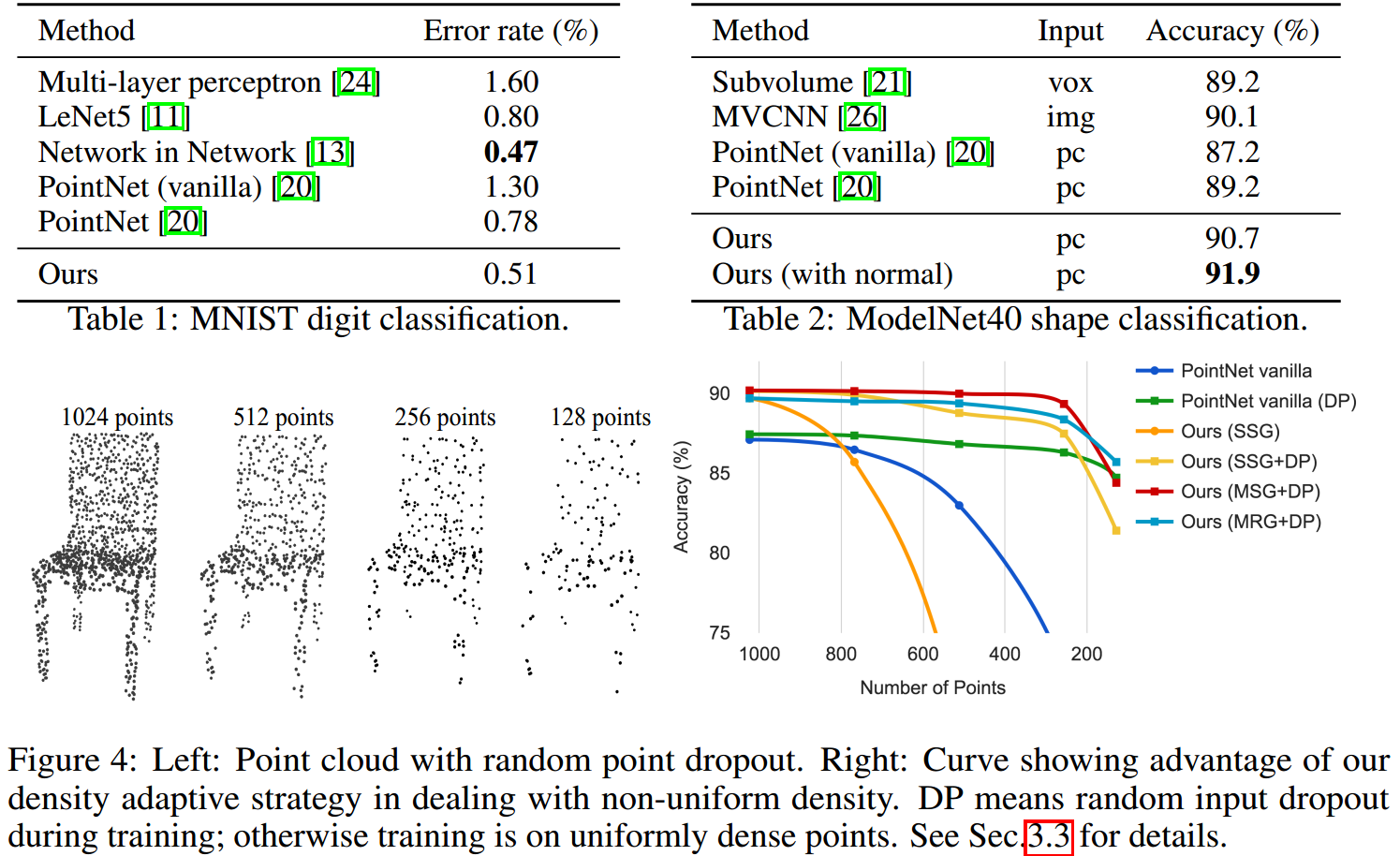
PointNet(vanilla)没有使用transformation network,即其等价于单层的PointNet++。
(with normal)表示使用了face normals作为额外的point features,另外使用更多的点(N=5000)来提高性能。
以上结果显示:
- 相比于PointNet,proposed model的性能确实提高了;
- 在2D image上的性能甚至可以媲美CNN;而在3D ModelNet40中,其超越了state-of-the-art(MVCNN)。
然后是测试了一下模型对于点的稀疏性的稳健性,结果在fig4中。
2. 点云分割
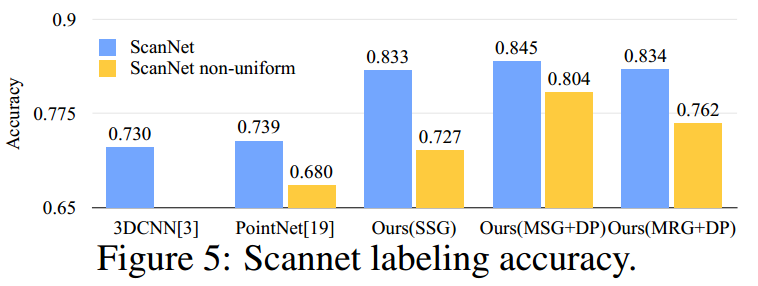
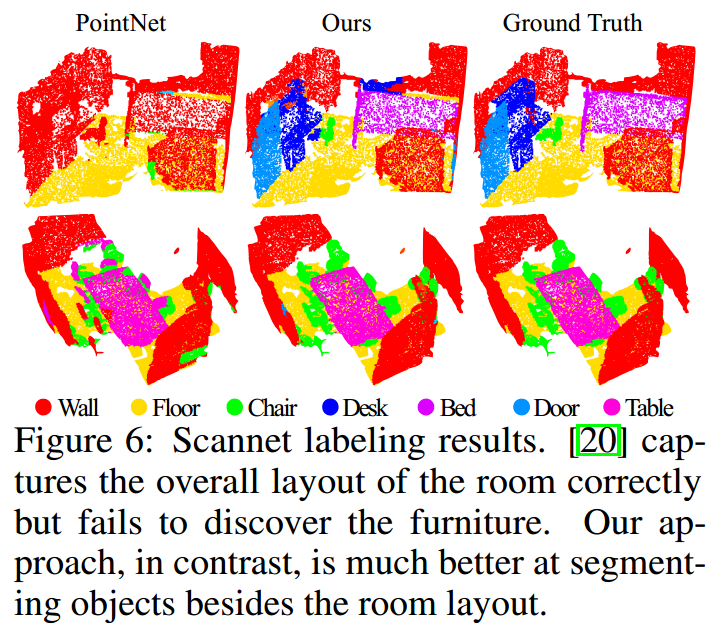
这里是和【5】进行的比较,【5】中没有使用RGB信息,所以这里也没有使用RGB信息。
3. 在非欧空间中的分类效果

在这样的任务中,a和c的点集表现完全不同,但也需要被分为相同的类型。

这里使用的metric是测地线距离,使用的特征也不是XYZ的特征(使用XYZ特征效果非常不好)。
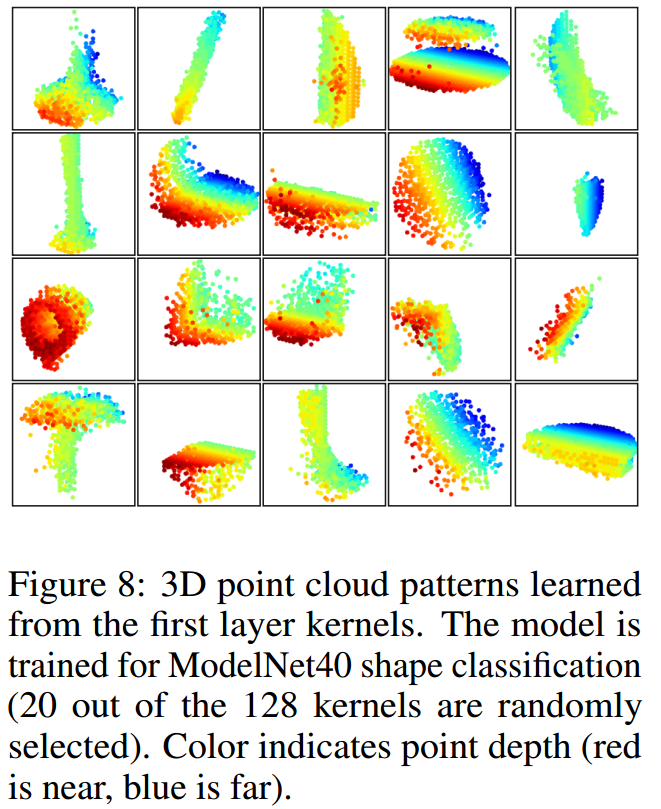
4. 特征可视化
这里将第一层set abstraction layer得到的特征点集进行可视化,发现其确实学到了一些点、面、角等特征,用来描述ModelNet4中的对象(其中大多数是家具)。
Conclusion
在未来,如何进一步提高MSG和MRG的运算速度,是一个需要考虑的问题。
Questions
文章中使用的网络架构在文章的附录中有介绍,这里加不去介绍这些细枝末节的东西了。这里需要注意一下,随着网络的加深,radius是逐渐增加的(因为点在变得稀疏嘛)。
其实它这个的实现和我之前读过的、更晚一些的一篇文章()已经非常像了。



