Communicative Representation Learning on Attributed Molecular Graphs
- 杂志: IJCAI-20
- IF: None
- 分区: None
- github
Introduction
准确预测分子性质是药物研究中一个重要的课题,这可以为下游药物开发节省大量的资源和时间【Cherkasov et al.2014】。
性质预测的主要思路:先将药物分子embed为一个dense feature vector,然后再对这个feature进行预测。
早期定量进行embed,主要通过特征工程的手段(QSPR),如:
- expert-crafted physicochemical descriptors 【Nettles et al.2007】
- molecular fingerprints 【Rogers and Hahn2010】
然而这些方法认为我们进行预测所需的信息都包括在这些特征中,这可能无法满足。
最近随着分子实验数据的增加,基于机器学习和深度学习的方法显示出明显的优势,其可以直接输入原始的、完整的分子表示(SMILES string或topological graph),从而学习到更加全面的信息。
- 本质上,任何一个分子都可以描述为一个hydrogen-depleted topological graphs,其中节点是原子(atoms)、边是化学键(bonds)。
- 【Duvenaud et al.2015】最早尝试使用GCN学习fingerprint。
- 【Gilmer et al.2017】总结了众多可用的架构,称为message passing neural networks(MPNNs),其在化学性质预测上都有较好的表现,即:
- message passing module:将每个节点的信息进行转换,并传送到它的邻接点上
- updating module:对于每个节点,基于其接受的信息,更新该节点的特征
但MPNNs类的方法没有考虑到edge上的信息。
为了解决上述edges的问题,【Yang et al.2019】提出了D-MPNN,其使用的是有向图
主要贡献是避免了不必要的信息循环,从而得到没有冗余的信息。
但其没有考虑到从bonds到atoms的消息传递,从而无法有效的捕获到更加全面的特征。
本研究提出了directed graph-based Communicative Message Passing Neural Networks(CMPNN):
- 其可以同时更新node和edge的特征;
- 为了避免冗余信息,精心设计了node interaction procedure;
- 提出了messager booster来丰富message生成;
Related Works
Descriptor-based Representation
最常用的descriptor就是分子指纹(chemical fingerprint),比如ECFP【Rogers and Hahn2010】。
我的理解,类似one-hot向量,每个变量表示是否存在某种结构。
一些基于fingerprint的DL方法,如【Dahl et al.2014】,表现出比传统ML方法更好的结果。
但其带来了以下两个问题:
- 数据过于稀疏,变量太多。
- 解释性不好。
Linear Notation-based Representation
此类中最常见的是SMILES notation,其基于共同的chemical bonding rules将topological graph进行编码。
一般处理这一类数据的NN都较为复杂:【[Zheng et al.2019b] [Jastrzebski et al.2016] [Zheng et al.2020] [Zheng et al.2019a]】
但序列表示的可扩展性差、空间信息的丢失是无法解决的问题。
Graph Structure-based Representation
- 【Duvenaud et al.2015】最早,将molecular映射为neural fingerprint,并逐渐有一批改进,这些共同构成了MPNN类的方法,但这类方法只考虑到了atoms information。
- 【Kearnes et al.2016】、【Gilmer et al.2017】和【Coley et al.2017】逐渐发展了将atoms和bonds都考虑其中的方法,这些方法因为是基于MPNN直接发展而来,所以在迭代过程中存在information redundancy。
- DMPNN【Yang et al.2019】将graph看做是一个edge-oriented directed structure,从而避免了unnecessary loops,减轻了information redundancy。
- 本研究基于DMPNN,将node-edge interaction module融入,从而充分利用atoms和bonds的信息。
Methods

Communicative Message Passing
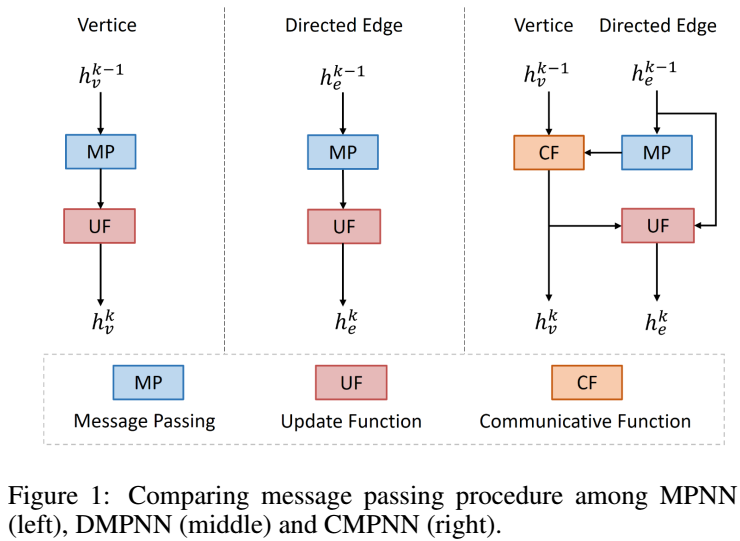
以上是MPNN、DMPNN、CMPNN在消息传递中的不同,可以看到:
- MPNN仅仅更新node特征;
- DMPNN只更新edge特征;
- CMPNN将node和edge特征都进行更新,并使用一个特殊的module进行操作。
算法如下所示:

可以看到:
先更新node特征:node message \(\mathbf{m}^{k}(v)\)来自指向它的edge features \(\mathbf{h}^{k-1}(e_{u,v})\)的聚合(这是最主要的和MPNN的不同),然后使用communicate func聚合message和原始特征更新node特征。
edge特征:原始edge \(\mathbf{h}^0(e_{v,w})\)和传递过来的edge message \(\mathbf{m}^k(e_{v,w})\)的计算
- 考虑原始edge特征\(\mathbf{h}^0(e_{v,w})\),相当于提供了一个skip connect【Yang et al.2019】
- 非线性函数\(\sigma\)是relu。
如果是DMPNN,这里的edge message是基于所有邻接边的特征\(\{\mathbf{h}^{k-1}(e_{u,v}),\forall u\in N(v)/w \}\)计算的。其没有考虑到其反向边特征\(\mathbf{h}^{k-1}(e_{w,v})\)。
也就是只考虑和目标edge有相同终点的edges。
在CMPNN中,因为node features中已经编码上述邻接边的特征,所以我们可以直接利用它,然后再减去目标edge的反向特征\(\mathbf{h}^{k-1}(e_{w,v})\)来作为edge message。
经过\(K\)层的特征特征更新后,再利用edge feature得到node message,然后使用communicate func将node message、node feature和原始node feature进行整合,得到最终的node features。
最后,使用一个readout函数(这里是GRU【Cho et al. (2014)】),将所有node features变换为一个向量\(\mathbf{z}\)。之后再接fc进行分类即可。
Message Booster
这里介绍上面的aggregate func。
- 【Hamilton et al.2017】提到了两种常用的aggregate func,即LSTM和max pooling。
- 【Xu et al.2018】则认为sum aggregattion要优于max/mean pooling。
- 【Yang et al.2019】也使用到了加和的方式来聚合邻接点特征形成message。
但以上的方式都没有考虑到edges间的关系,所以本研究提出了message booster的方式来进行aggregate得到message,如下图所示:
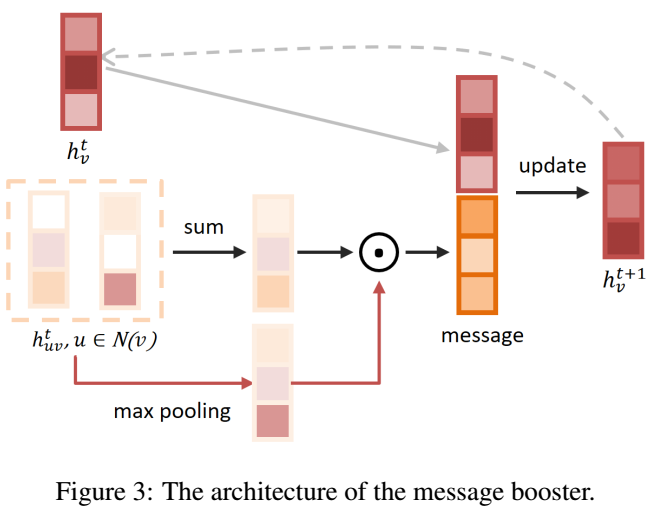
公式为:
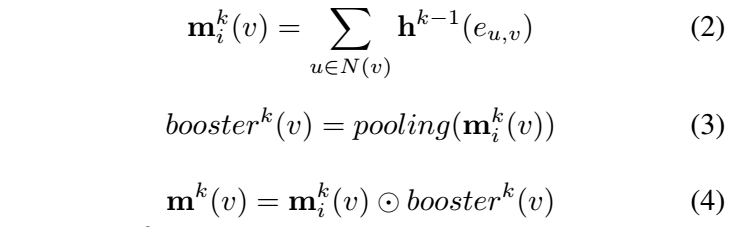
这个公式可能写错了,实际上就是将所有node features,做了一次sum和max,然后乘起来即可。下面的公式可能更加正确: \[[\sum_{u\in N(v)}{\mathbf{h}^{k-1}(e_{u,v})}]\odot [\max_{u\in N(v)}{\mathbf{h}^{k-1}(e_{u,v})}]\]
实际上就是sum和max的结合。mean pooling是不可取的,max可能是最好的,但会丢失一些信息,sum可以进行一定的弥补。
Node-Edge Message Communication
这里介绍communicate func,在MPNN和DMPNN中称为updating step。
这里有3种备选方案:
Inner product kernel:
\[\mathbf{h}^k(v)=\mathbf{m}^k(v)\odot\mathbf{h}^{k-1}(v)\]
Gated graph kernel【Li et al.2015】:
\[\mathbf{h}^k(v)=GRU(\mathbf{h}^{k-1}(v), \mathbf{m}^k(v))\]
GRU有更强的拟合能力,但其不是symmetric的,这和graph的性质略有不符。
Multilayer Perception:
\[\mathbf{h}^k(v)=\sigma(W \cdot Concat(\mathbf{h}^{k-1}(v), \mathbf{m}^k(v)))\]
Results
实验设置
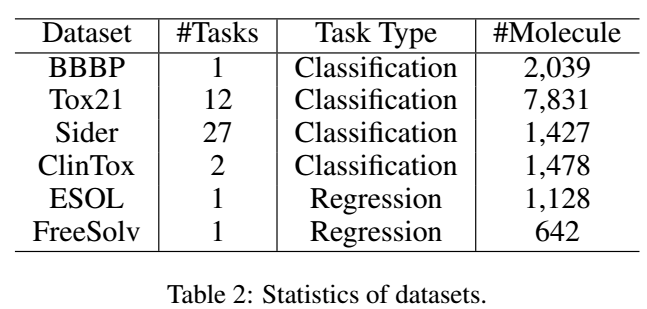
一共有6个benchmark datasets:
- BBBP,血脑屏障穿透数据集,记录的是化合物的穿透性。
- Tox21,预测12个和药物毒性有关的靶点。
- Sider,已上市药物的27个器官的毒性反应。
- ClinTox,包括了FDA审批通过的药物和因为药物毒性没有通过的药物。
- ESOL,化合物的水溶性。
- FreeSolv,水化自由能。
其中Tox21、Sider、ClinTox是多任务学习。
比较的方法有9种(+CMPNN):
- binary Morgan fingerprints + RF
- binary Morgan fingerprints + FNN(MLP)
- GCN【Kipf and Welling2016】
- Weave【Kearnes et al.2016】
- N-Gram【Liu et al.2019】(unsupervised)
- RGAT【Ryu et al.2018】
- MPNN
- DMPNN
使用5-CV,分割策略有random和scaffold-based两种。评价指标是AUC和RMSE。使用的节点特征使用开源库RDKit计算得到。超参数使用Bayesian Optimization搜索得到。
scaffold-based split是一种更加接近现实、更加有挑战性的数据集分割方式,可以通过python module RDKit实现。
实验结果
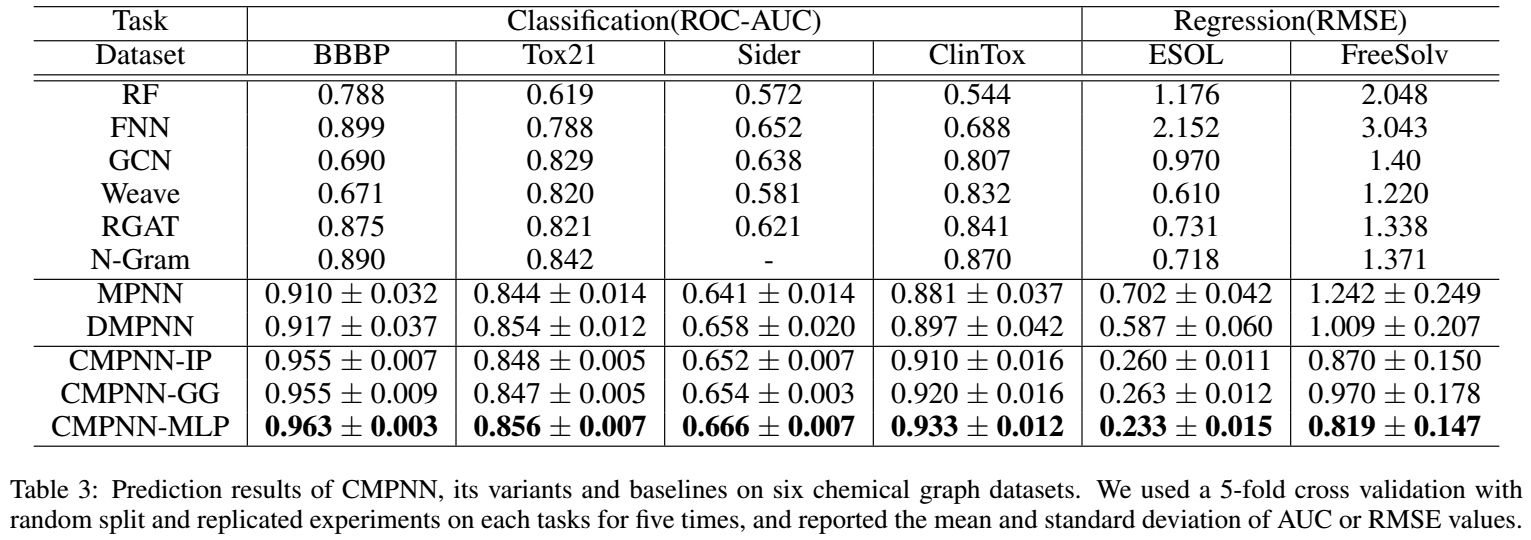
可以看到,CMPNN取得了非常好的结果。
因为Tox21的不平衡性,这里使用scaffold-based split进行进一步的验证:
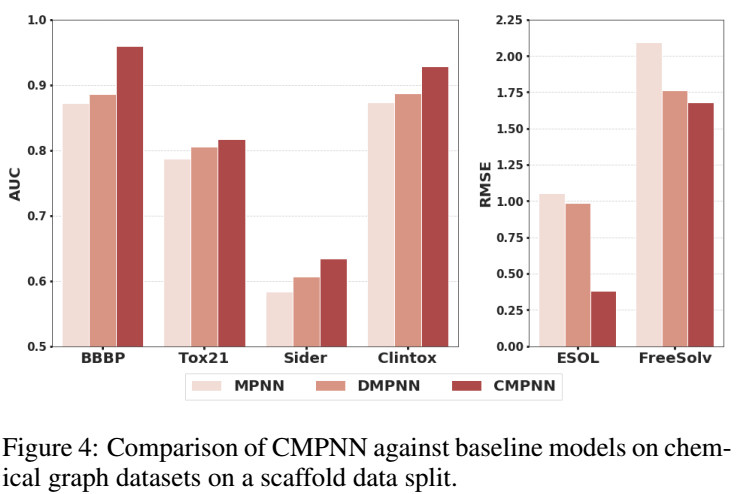
消融实验
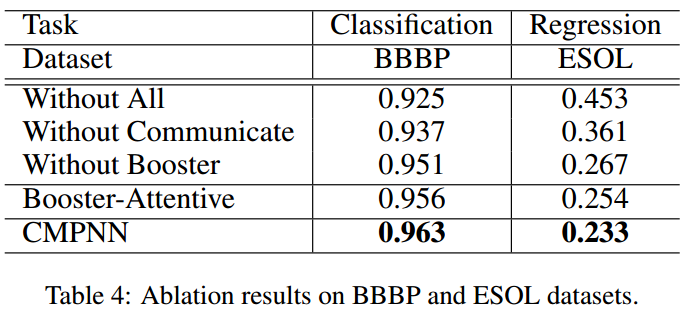
证明了message booster和communicate func的重要性,也和attention-based booster进行了比较。
特征可视化

分子特性通常和其结构密切相关,为了证明CMPNN能够学习到更好的特征,这里对学习到的特征进行可视化。
- 匹配PAINS database(包含有400个毒性子结构),从Tox21中选择出100个毒性分子,然后对应的选择出100个非毒性分子。
- 将每个分子(graph)中的atoms(node)对应的标记成toxic和non-toxic。
- 利用上述方法学习这些atoms的特征,然后使用t-SNE进行可视化。
从上图可以看出,CMPNN有更好的效果。
Conclusion
本研究通过增强bonds和atoms间的信息交互,从而提高了预测性能。



