Conditional Image Generation with PixelCNN Decoders
- 杂志: NIPS
- IF: None
- 分区: None
Introduction
使用NN进行image modelling的研究众多,并且已经能够产生多样的图片。但实际应用中,我们一般需要conditioned on prior information。
本研究通过对PixelRNN【30】进行改进,加入卷积来实现conditional image modelling,使用的是自回归的方法,并且有明确的概率密度估计。
原始文献【30】中的pixelRNN和pixelCNN有着不同的缺点:pixelRNN更加准确,但很慢;pixelCNN更快,但估计不如RNN准确。
本研究提出了Gated PixelCNN,既能够有准确的估计,而且速度也有保障。
另外,本研究还提出了Gated PixelCNN的conditional版本,能够根据一些条件、标签了生成图像。
Methods
![]()
PixelCNN
上图展示了pixelCNN的基本原理,基本来说,还是遵循了AR模型的假设,需要逐个对像素点进行条件概率建模,其依赖于其前面的像素点。
pixelCNN在此基础上使用masked CNN来进行建模,其卷积核如上图middle所示。每个位置上,先建模R、然后是G、最后是B。最后使用256-softmax来输出一个像素值的概率。所以pixelCNN输入\(N\times N\times3\),输出\(N\times N\times3\times256\)。
进行采样时,和传统的AR模型一样,逐个pixel的生成。
但pixelCNN有下面的缺点:
相比于pixelRNN来说,其效果较差。
这可能是因为pixelCNN相对于pixelRNN来说,其所能访问的像素点范围是随着NN的深度线性增加的,所以当网络不够深时,其无法向pixelRNN一样访问到之前所有的像素点。
另外,pixelCNN缺乏multiplicative units(LSTM中的门控单元),这些units将有助于构建更加复杂的关系。
盲点。
如上图右上方所示,当使用3x3卷积的时候,随着卷积的增加,进行某个像素点的概率估计的时候,有一部分内容是看不到的,是blind spot。如果有重要的信息在此,可能会影响模型的训练。
Gated PixelCNN
本研究针对上面两个问题,进行了如下的改进:
每一层将relu替换为gated units,从而增加multiplicative units,增加NN的拟合能力:
\[\mathbf{y}=tanh(W_{k,f}\star\mathbf{x})\odot\sigma(W_{k,g}\star\mathbf{x})\]
其中,\(\odot\)表示element-wise product,\(\star\)表示convolution,后面的是gated,使用tanh替代relu。gated units可以形成类似highway networks的效果,从而有助于模型的效能提升。
针对blind spot的问题,我们使用两个convolutional network的stacks来解决这个问题:其中一个用来聚合像素点上面的行的信息(vertical stack),另一个用来聚合像素点所在行前面的像素点的信息(horizontal stack)。如果上图右下角所示,而下图展示了单层的设计:
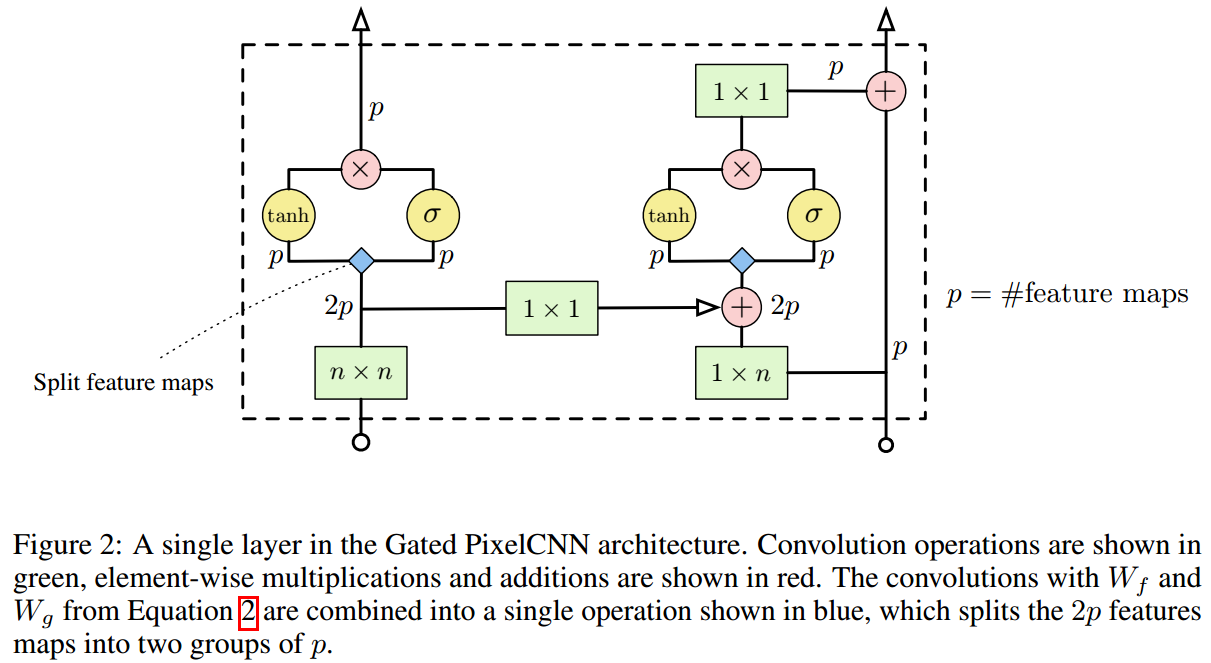
注意:
每一层接受两个输入,必须输出两个结果,分别是horizontal stack和vertical stack。horizontal stack的输出将作为下一层horizontal stack的输入,vertical stack的输出也将作为下一层vertical stack的输入。
实现两个stack,可以使用mask(上图是\(n\times n\)和\(1\times n\)的卷积核,说明使用了masked),也可以使用正常的长方形卷积进行,然后通过padding、cropping和shifting来进行调整,使其卷积得到的信息是提供给我们想要的pixel。
在我看来,就算是使用mask,也必须配合shift(在最后一层进行)才行。
horizontal stack的输出可以来自混合了horizontal stack和vertical stack的信息,这并没有破坏AR的conditional rules。
但vertical stack的输出不得混合horizontal stack的信息,这将破坏conditional rules。
Conditional PixelCNN
所以现在我们需要建模的分布是:
\[p(x|\mathbf{h})=\prod_{i=1}^{n^2}{p(x_i|x_1,\dots,x_{i-1},\mathbf{h})}\]
这个通过在每一层都加入\(\mathbf{h}\)的信息来实现:
\[\mathbf{h}=tanh(W_{k,f}\star\mathbf{x}+V_{k,f}^T\mathbf{h})\odot\sigma(W_{k,g}\star\mathbf{x}+V_{k,g}^T\mathbf{h})\]
这里认为\(\mathbf{h}\)表示的是图像中有什么物体出现或者出现的内容,但并不指定物体的位置等等,所以其不包含位置信息。
如果想要进行\(\mathbf{h}\)包含位置信息的建模,可以使用下面的模型:
\[\mathbf{h}=tanh(W_{k,f}\star\mathbf{x}+V_{k,f}\star\mathbf{s})\odot\sigma(W_{k,g}\star\mathbf{x}+V_{k,g}\star\mathbf{s})\]
其中\(\mathbf{s}=m(\mathbf{h})\),\(m\)是一个deconvolution,\(s\)是一个长宽和\(\mathbf{x}\)相同的特征图,\(V\)是\(1\times1\)卷积。
PixelCNN AE
对传统的AE进行修改,将decoder部分改变为conditional PixelCNN,其接受的\(\mathbf{h}\)是encoder的输出。
Results
Unconditional Modeling
首先是在CIFAR-10上的结果:
![]()
之后在Imagenet上的结果(20 layers、每个layers有384个hidden、kernel size是5x5、batch size是128):
![]()
Conditioning on ImageNet
![]()
Conditional on Portrait Embeddings
![]()
![]()
PixelCNN AE
![]()
Conclusion
其实从上面的结果来看,即使在32x32的图片上,实际效果也着实一般。但总归是有提高的。
未来的一个思路是使用PixelCNN替代VAE的Gaussian,从而提高VAE的性能。
实际上,后来的VQ-VAE就是通过以上的方案实现的。
Questions
- 现在因为有3个染色通道,怎么序列的进行r、g、b的建模的?
- 很多细节需要在代码中才比较好理解...



