Hierarchical Graph Representation Learning with Differentiable Pooling
- 杂志: None
- IF: None
- 分区: None
Introduction
- 当前已经有许多GNN的工作,在社会网络【16,21,36】和分子网络【7,11,15】,其基本思路是将整个graph看做一个计算图,然后通过信息的passing、transform、aggregation等来学习node embedding,之后再使用学习到的node embedding来进行node classification【16】或link prediction【32】;
- 但以上的GNN的主流方法只能通过graph的结构传递信息,无法分层的推断或汇总信息,这让进行graph classification任务称为挑战,只能使用简单的global pooling【7,11,15,25】;
- 本研究提供出了DiffPool方法(fig1),其可以在更深的网络中学习graph的分层表示。灵感来源于CNNs,但为了避免因空间信息的缺失而带来的挑战,DiffPool使用一个堆叠的GNN来学习nodes间的聚类关系,这个GNN也有参数需要进行训练;
- 本研究中实验证明DiffPool的有效性,平均提高了7%的准确性,而且在4(一共5个)个graph classification benchmark上达到了state of the art。
相关工作
GNN;
GNN的graph classification【7,11,40】:
- 简单的sum或average所有的node embedding【11】;
- 使用一个virtual node来连接所有的nodes【25】;
- 使用一个deep leanring architecture来学习聚合所有的nodes【15】;
以上的方法都存在无法学习graph中分层信息的缺点,另外还有一些试图将CNN的架构应用到GNN中【29,40】,但这需要指定nodes的一个排序,这本身是困难的;
还有一些工作试图先通过graph cluster方法【8,35,13】来确定性的学习graph层次,然后应用到GNN中;
Methods
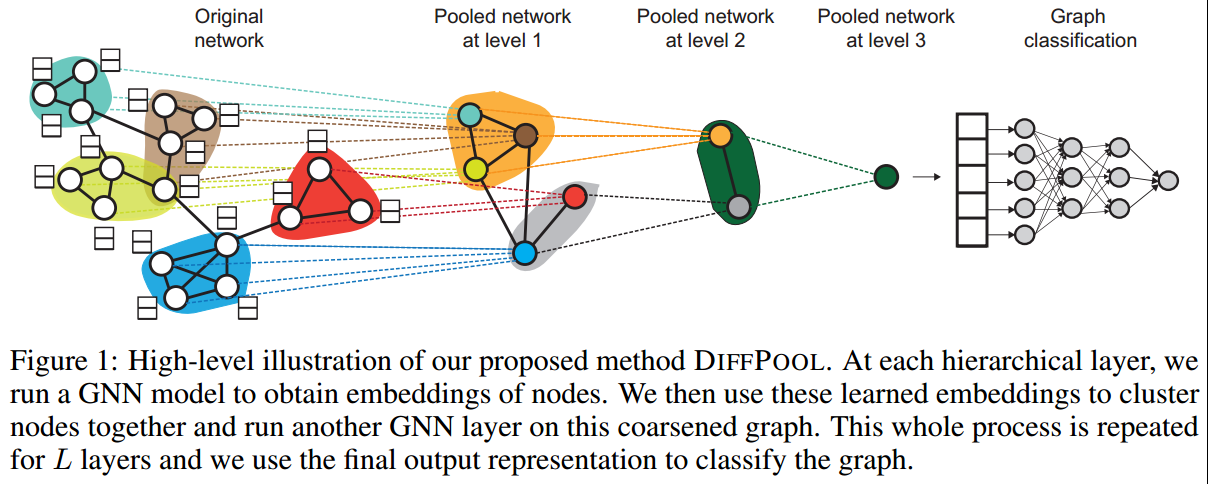
问题框架
- graph被表示为\((A,F)\),其中\(A\)表示adjacency matrix,\(F\in\mathbb{R}^{n\times d}\)表示nodes features,数据集表示为\(\mathcal{D}=\{(G_1,y_1,\dots)\}\);
- 我们的任务是学习一个映射\(f:\mathcal{G}\to\mathcal{Y}\),其中的难点在于如何将一个graph表示为一个确定维度的向量表示;
以上问题可以使用GNN来解决。假设这个GNN符合下面的message-passing框架: \[H^{(k)}=M(A,H^{(k-1)};\theta^{(k)})\tag{1}\] 其中\(M\)是message propagation function,\(H\)表示学习到的node embedding,\(\theta\)表示学习的参数。
\(M\)的实现有多种方式,比如Kipf的GCNs \[H^{(k)}=ReLU(\widetilde{D}^{-\frac{1}{2}}\widetilde{A}\widetilde{D}^{-\frac{1}{2}}H^{(k-1)}W^{(k-1)})\tag{2}\] 其中\(\widetilde{A}=A+I\),\(\widetilde{D}=\sum_j\widetilde{A}_{ij}\)。一般堆叠2-6层即可。
在以上研究的基础上:
本工作的目的在于定义一个通用的、端对端的框架允许hierachical地进行学习,即:
存在一个pooling,返回一个新的graph,nodes数量\(m<n\),adjacency matrix \(A'\in\mathbb{R}^{m\times m}\),和新的node embedding \(Z'\in\mathbb{R}^{m\times d}\),通过在GNN中多次插入这样的模块使得GNN能够逐渐处理越来越“粗”的graph;
关键在于如何学习cluster方式。
DiffPool
基本思想是:堆叠L层的GNN来学习生成cluster的分配矩阵。
首先介绍,如果使用分配矩阵进行pooling
在第\(l\)层定义一个分配矩阵\(S^l\in \mathbb{R}^{n_{l}\times n_{l+1}}\),注意是软分布策略(其中的元素是连续的数值);
然后下一层的节点特征和邻接矩阵可以由以下方式计算:
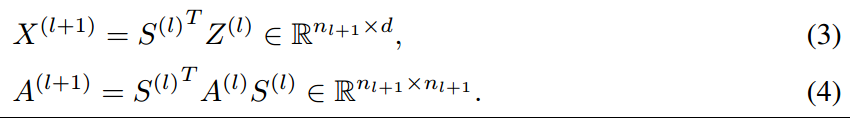
注意到,因为使用的是软分配策略,所以得到的\(A^(l+1)\)是全连接的edge-weighted graph,其第\(ij\)个值表示的cluster \(i\)和cluster \(j\)的连接强度;
如何得到分配矩阵
由上面可知,进行pooling需要两个东西:\(S\)和\(Z\),这里这两者都通过GNN将原始节点特征转换而来:
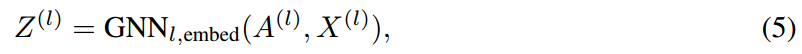
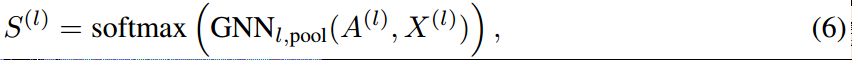
其中softmax是row-wise的(每一行加在一起为1,即每个节点分配后,加在一起还是原来的那一个)。
另外,可以证明,DiffPool操作而是permutation invariant
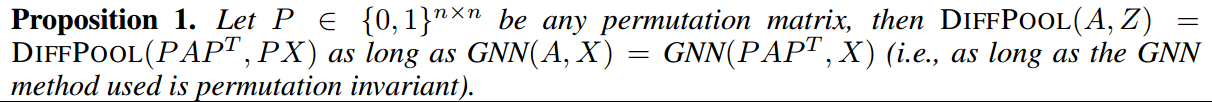
只要是DiffPool中使用的GNN是permutation invariant,则可以证明整个DiffPool就是permutation invariant
辅助训练
实际上,直接训练上面的框架是困难的,需要额外加入一些辅助训练loss或者说regularizations:
应该试图将邻接点合并在一起,即对于每一层,最小化:
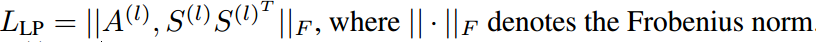
其中对于深层的GNN,\(A\)就是上一次进行pooling后得到的网络。
另外,式6的softmax输出应该尽可能的接近one-hot向量使得我们比较清楚地知道nodes应该属于那个cluster,所以还需要最小化每个softmax概率的entropy:
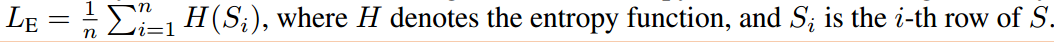
Results
目的
- DiffPool相比于其他GNN pooling方法(sort pooling【40】和Set2Set【15】)相比,是不是更好?
- DiffPool和GNN结合后,在graph classification任务上和其他方法进行比较?
- DiffPool得到的cluster是否可以进行有效的解释?
数据集
- Protein data sets:ENZYMES、PROTEINS、D&D;
- Social networks:REDDIT-MULTI-12K、COLLAB;
相关统计学指标见Appendix A;
所有的指标使用的10-cv后的平均acc评价。
模型超参数
- 使用的是graphSage中的mean variant【16】,并每隔2个graphSage加一层DiffPool,对于小型数据集(ENZYMES、PROTEINS、COLLAB)一层DiffPool也能取得类似性能;
- 在进行下一个pooling或readout之前进行3层graph convolution;
- 如果是2个DiffPool,则pooling后的nodes数量设为之前的25%,如果是1个DiffPool,则设为10%;
- 每个graphSage都应用了BN,并且在每个nodes embedding上加l2正则化会稳定训练;
- 训练了3000个epochs,并在验证集随时不再下降的时候使用了early stop;
- 另外,为了评价DiffPool中的一些组件的功能,还有两个简单版本的DiffPool:
- DiffPool-set,其分配矩阵是通过确定性的graph聚类算法得到的;
- DiffPool-nolp,没有link prediction辅助训练;
基线方法
- 基于GNN的方法:
- GraphSage,带有mean-pooling【16】,其他变种没有使用,因为【21】证明了GraphSage在此类任务上效果是最好的;
- Structure2vec【7】,使用的是global mean pooling;
- Edge-conditional filters(ECC)【35】使用图粗化算法来进行pooling,并考虑了edge information到GCN model中;
- PatchySan【29】定义了每个节点的receptive field,并使用规范的节点排序来进行卷积;
- Set2Set【38】;
- SortPool【40】;
执行10-CV来得到最后结果,并联系原作者得到其代码来进行实验,并按照原始作者的思路进行超参数搜索;
- 基于kernel的算法:GRAPHLET、SHORTEST-PATH、WEISFEILER-LEHMAN(WL)、WL-OA kernel作为baseline,使用的是C-SVM分类器,其中\(C\in\{10^(−3),10^(−2),\dots,10^2,10^3\}\),通过10-CV确定,对于WL和WL-OA,从\(\{0,\dots,5\}\)中搜索迭代次数。
Graph分类结果
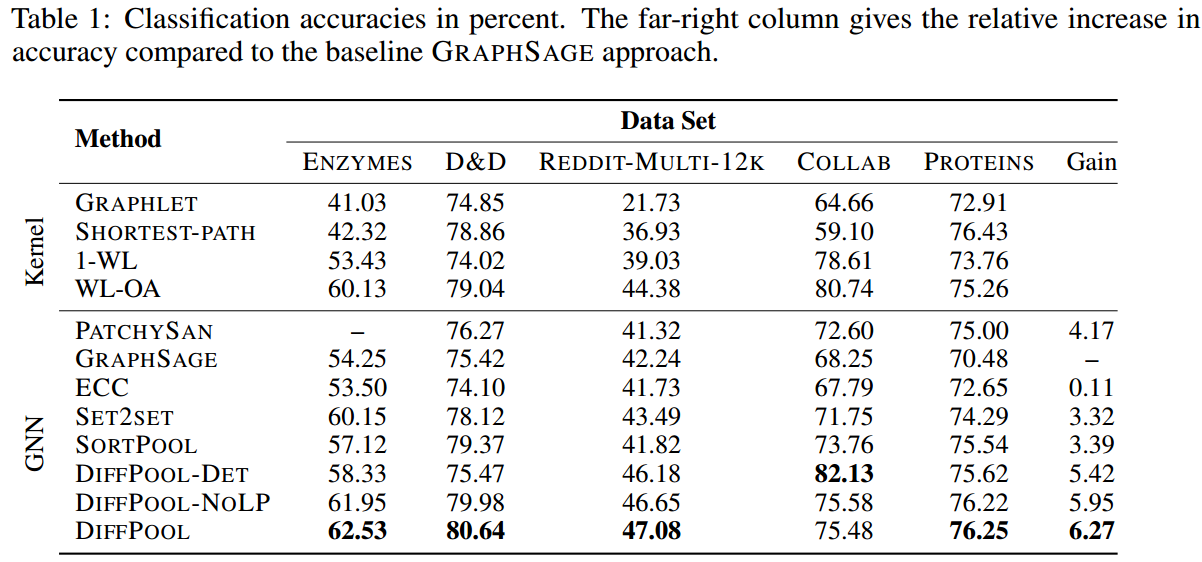
- 这个结果回答了问题1和问题2,即DiffPool有更加好的性能,平均来说比graphSage提高了6.27%,并在4个benchmark上有最佳效果。在collab上则是确定性的聚类有更好的效果,这是因为collab的网络有许多社区结构,仅通过聚类算法就已经能够很好的捕获了,所以实现了更好的效果;
- 另外,DiffPool算法在经过Link Prediction限制后,有更好的稳定性;
另外我们将DiffPool应用到了另外的S2V模型上,以证明DiffPool可以应用到不同的GNN模型框架中:
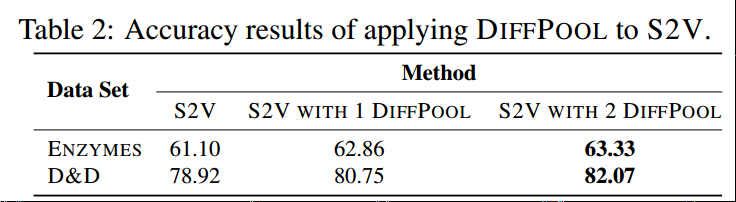
发现DiffPool也使S2V模型的效果得到提升,在其他数据集上也有类似的结果。
至于运行时间,发现DiffPool并不会招致大量的额外时间,因为减小了网络大小。带有DiffPool的GraphSage模型比带有Set2Set的GraphSage要快12倍,而且有更高的准确性。
聚类分配结果分析
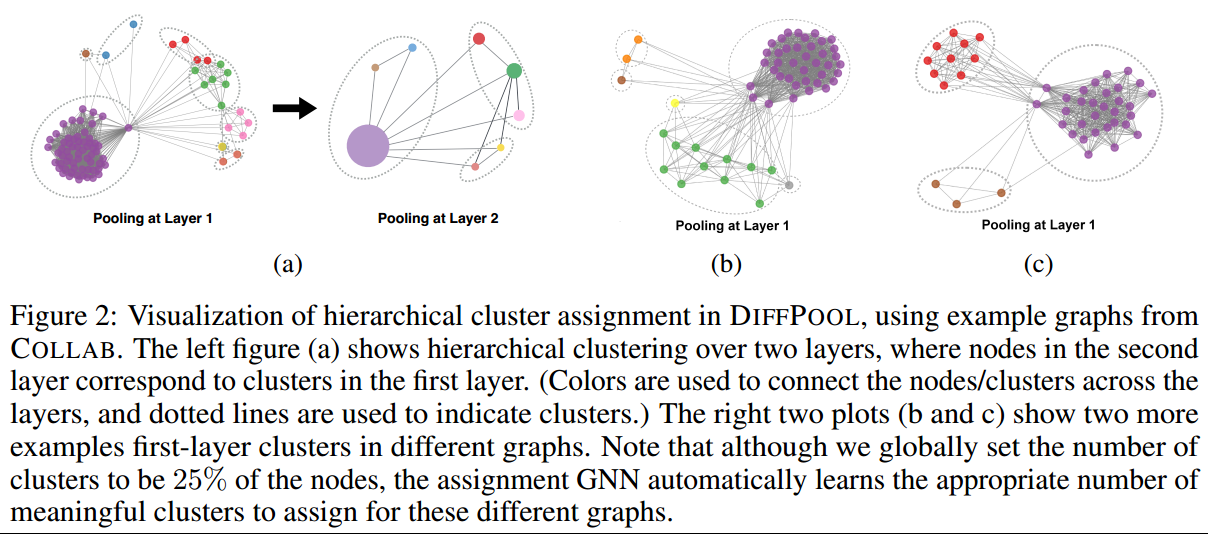
- 分层聚类结构:DiffPool得到的分层结构展示在fig2中(COLLAB),其中颜色代表其属于的cluster类别,我们观察到了明显的分层社区结构,尽管其只通过分类来学习的。有辅助训练的分配质量会有所提高;
- DiffPool得到的是密集连接的图,这可能会减少损失的信息;
- 有相似表示的nodes会被分配到在一起,比如距离非常远的两个节点,但其与周围邻居的连接模式相似,则两者可能会被分配到相同的cluster中,这和image ConvNets不同;
- 结果对cluster的数量敏感。大的cluster数量可能会导致更大的噪声和更低的效率;
Conclusion
本研究提出了一种可微分的池化方法,能够提取复杂的层次结构。和现有的GNN模型结合后,在benchmark上取得了非常好的结果。
未来的一个研究方向是去进行hard cluster assignment,可以降低计算成本,同时还确保了可区分性;另外还需要将其应用于其他的任务上,探索其在分类以外任务的能力。
Questions
针对这个方法,实际上我有自己的思路进行改进,基本的想法和其在结论中提到的一致,即hard cluster assignment:
- 使用gumbel softmax来进行分类采样,这样可以引入一定的随机性,而且还变成了hard cluster assignment,可能会提高效率;
- Gumbel softmax的使用引入了另外的思想,即将分配看做是一个隐变量,使用变分推断的思想来进行训练,但如果存在多个pooling层,我们需要想想如何解决?



