Towards Graph Pooling by Edge Contraction
Edge Contraction Pooling for Graph Neural Networks
这里搜到两个题目,但其实内容是一样的,其中第一篇较为粗糙,第二篇精细一些。
- 杂志: None
- IF: None
- 分区: None
Introduction
- 使用deep learning来对graphs进行处理是进来的一个热点,其中许多启发自CNNs,关于其中pooling layers的研究却显得欠缺。
- pooling的作用是非常显著的:确定clusters、减少计算复杂度
- 本研究提出一种新的基于edge contraction的pooling layer——EdgePool,其不再去选择保留哪些nodes,而是去选择保留哪些edges。

相关工作
这里可以将所有的pooling分为两种:直接进行pooling和学习进行pooling。
- DiffPool,学习进行pooling。
- Graph U-net,学习进行pooling。【Cangea et al.(2018)】使用其去进行graph classification。
- SAGPool,学习进行pooling。
Methods
Edge Contraction Pooling
首先为每条edge计算一个score。本研究使用的是下面的过程:
\[r(e_{ij})=W(n_i||n_j)+b\]
其中\(n_i\)和\(n_j\)是node features,此得到的是raw score。如果存在edge features \(f_{ij}\),则我们可以这样得到raw score: \[r(e_{ij})=W(n_i||n_j||f_{ij})+b\]
然后有两种不同的construction methods:
tanh:计算edge score为\(s_{ij}=tanh(r_{ij})\)
softmax:即以某个节点为target,将其neighborhoods的raw scores进行softmax-normalize,即\(s_{ij}=softmax_{r_{\star j}}(r_{ij})\)
(在后一个版本的文章里只有这个计算方法)\(s_{ij}=0.5+softmax_{r_{\star j}}{r_{ij}}\)
按照上面的公式,好像是沿adjacency matrix的列进行的normalization。
然后,将edge scores从大到小进行排序,依次将排名靠前的edge连接的nodes放在一起(如下图所示)形成一个新的节点,而该节点连接到和原来的两个节点有链接的所有节点。
依次重复进行这个操作,直到聚合了graph中50%的节点。
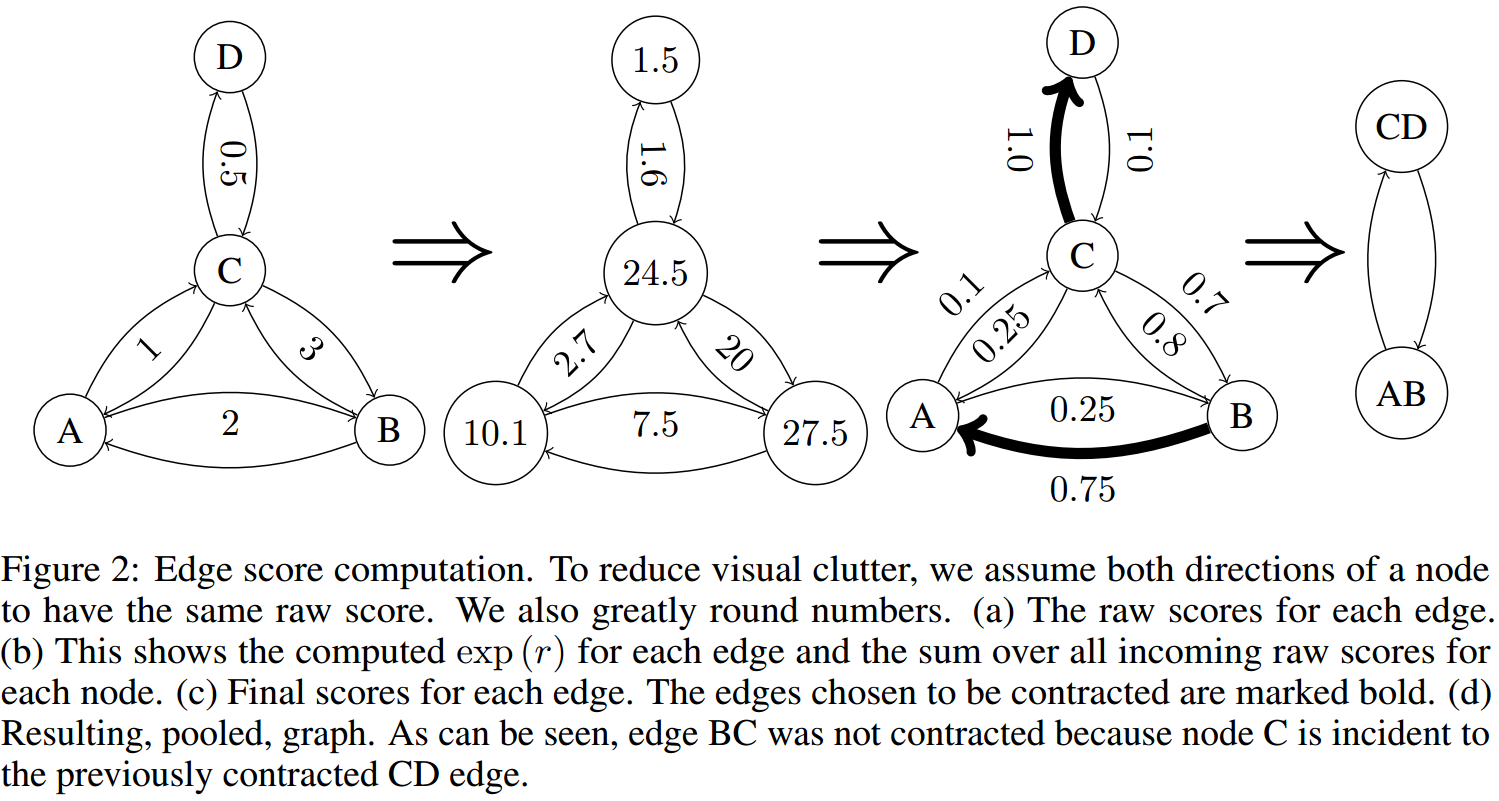
聚合node features
本研究发现,使用最简单的sum就可以取得较好的效果。另外,为了能够保证梯度的流动,所以还需要乘以edge score:
\[\hat{n}_{ij}=s_{ij}(n_i+n_j)\]
Unpooling EdgePool
如果进行node classification并使用Graph U-net的架构来完成,则还需要Unpooling EdgePool。
这里的做的是:首先将graph的结构复原,然后将“聚合点”的特征除以其对应的edge的score作为新的分离点的特征。 \[\hat{n}_i=\hat{n}_j=n_{ij}/s_{ij}\]
- 优点:整个计算是sparse的,所以计算量和内存占用都比较小;其影响只在需要进行pooling的edges上进行,所以对于大型的graphs或变化的graphs有计算优势。
- 缺点:每次都让nodes的数量减半,这无法由用户控制。
Results
回答两个问题:
- EdgePool是否要优于TopKPool和DiffPool?
- EdgePool是否可以作为一个即插即用的GNN组件?
- EdgePool是否可以用于node classification?
评价过程
使用的graph classification数据集是来自【Kersting et al. (2016)】:PROTEINS、两个reddit-based datasets、COLLAB。
使用的node classification数据集是5个semi-supervised node classification datasets:CORA、CITESEER、PUBMED是3个citation networks,PHOTO、COMPUTER是2个Amazon co-purchasing graph。每次使用20 nodes per class来训练,30 nodes per class来测试。其他节点是unlabelled。
训练时,使用Adam,200 epochs,lr是10-3(每50个epochs减半),batch size是128。
PROTEINS使用的channels是64,其他使用128。【Ying et al. (2018)】所有的模型都有dropout和batch normalization。另外,发现对edge score使用dropout会显著提升EdgePool's的性能,这里设置drop probability是0.2。
使用10-fold cross-validation,报告mean和std。
模型架构
对于第一个问题:
使用3个SAGEConv blocks和3个pooling交替堆叠而成,然后接一个global mean pooling。将3个block的输出和global pooling的输出concat后接两层fc进行分类,base model不适用pooling。SAGEConv blocks和模型的详细情况见下图:
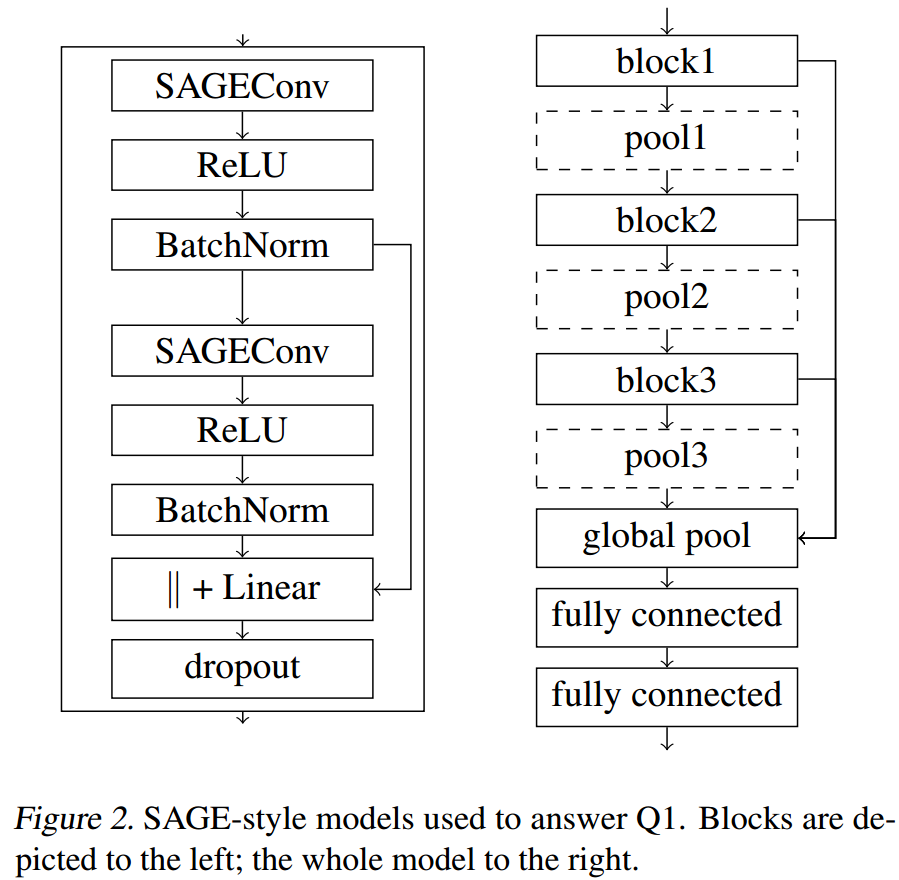
DiffPool限制为每个graph最多750个nodes,TopKPool使用rate为0.5使得其和EdgePool一致。
loss使用cross-entropy loss,为了保证一致,DiffPool训练时没有使用additional auxiliary losses。
对于第二个问题:
我们将使用不同的GNNs layers来配合EdgePool形成model,并查看其效果。使用的GNNs有:GCN、GIN、GIN0、GraphSAGE、GraphSAGE na。
网络架构如下图所示:
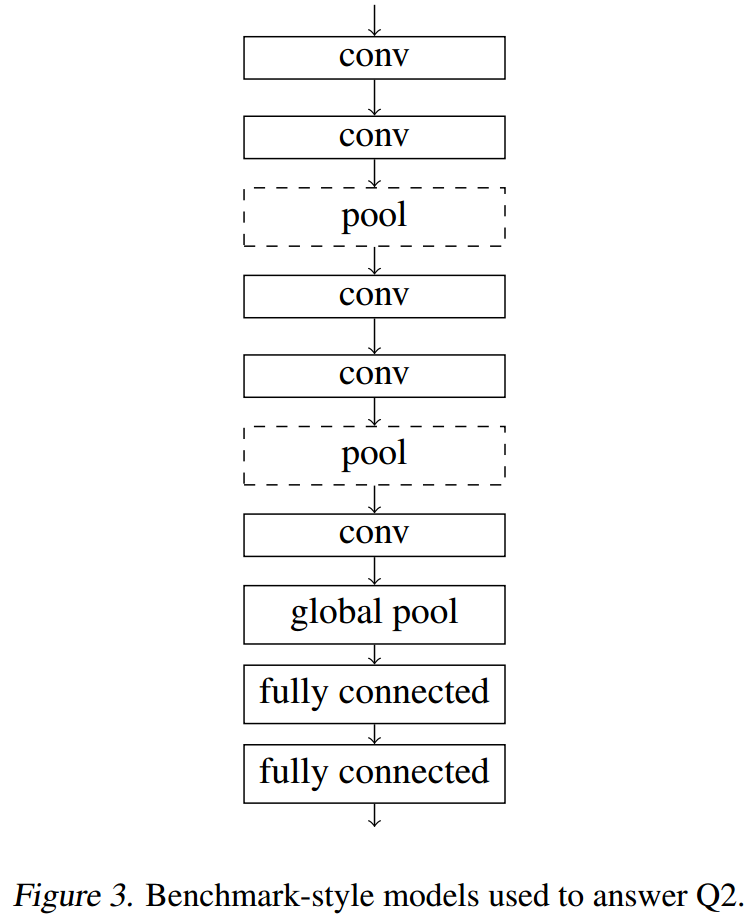
对于第三个问题:
评价的GNN类型有GCN、GIN、GIN0、GAT,另外还评估了MLPs的效果。
这里的网络架构类似第二个问题,但有7层conv layers。其中第2、4层后使用pool,第5、7层后使用unpooling,然后在pooling和unpooling间使用shortcuts(U-Net)。然后将concated的features使用2-layers MLP来预测node class。
评价指标
下面是关于第一个问题的实验结果:
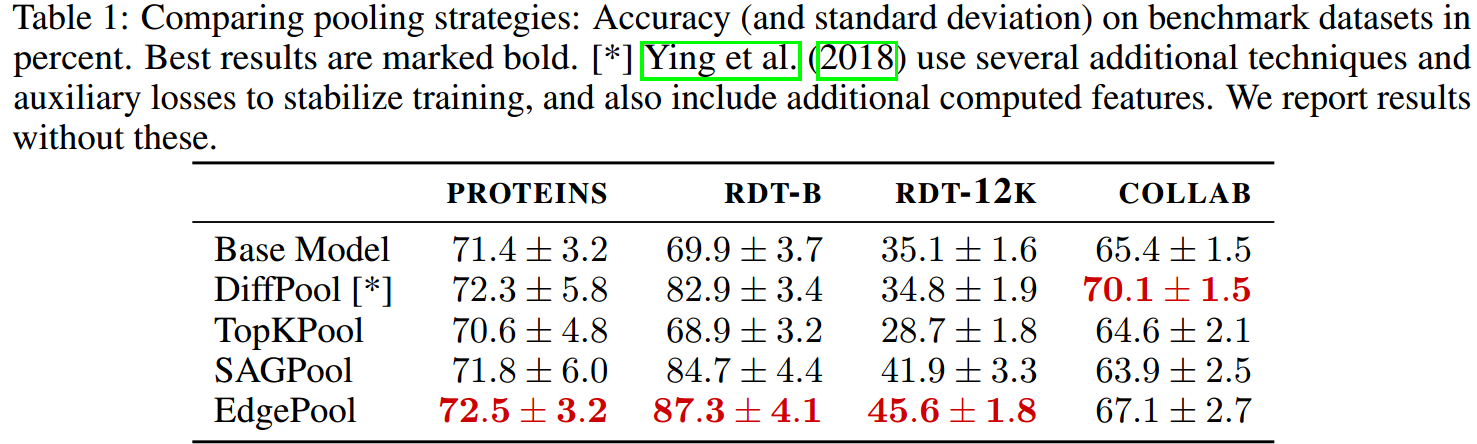
EdgePool在3个数据集上取得最佳效果,而且仅在一个数据集上次于DiffPool。EdgePool“伸缩性”更好,可以在更大的graph上使用。
下面是关于第二个问题的实验结果:
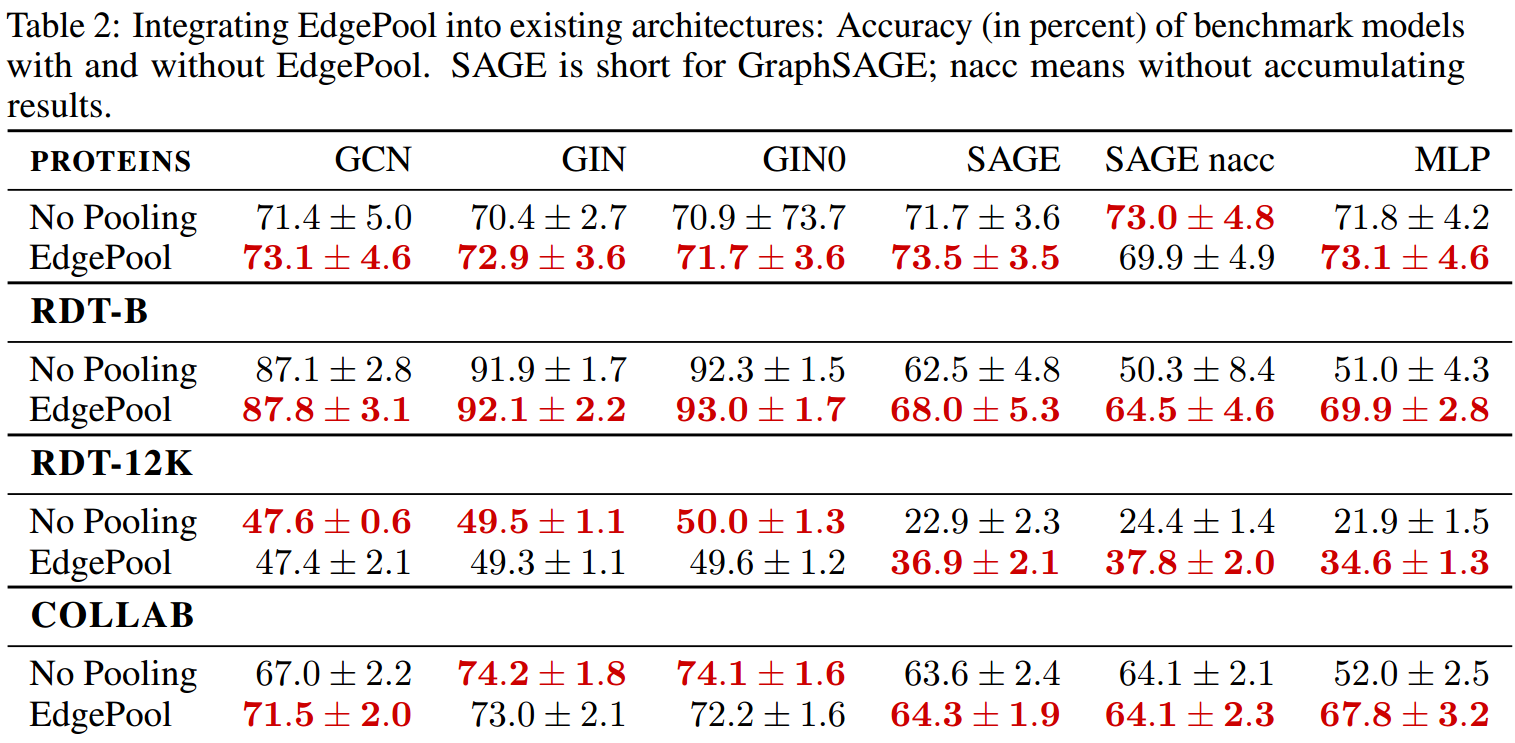
可以看到,大多数情况下EdgePool都带来了性能的提升(平均2.2个百分点)。其中在GIN和GIN0上提升最小(0.3个百分点),在GraphSAGE上提升最大(5.5个百分点)。
对于MLP,我们可以发现,EdgePool都有提升。MLP并不能自动地联系各个节点之间的信息,只有插入其中的pooling能够做到,EdgePool能够普遍地带来提升意味着其能够完成这个任务。
但遗憾的是,引入pooling带来的性能提升与使用的数据集和模型都有关系,所以我们无法做出一个明确的建议。
下面是关于第三个问题的实验结果:
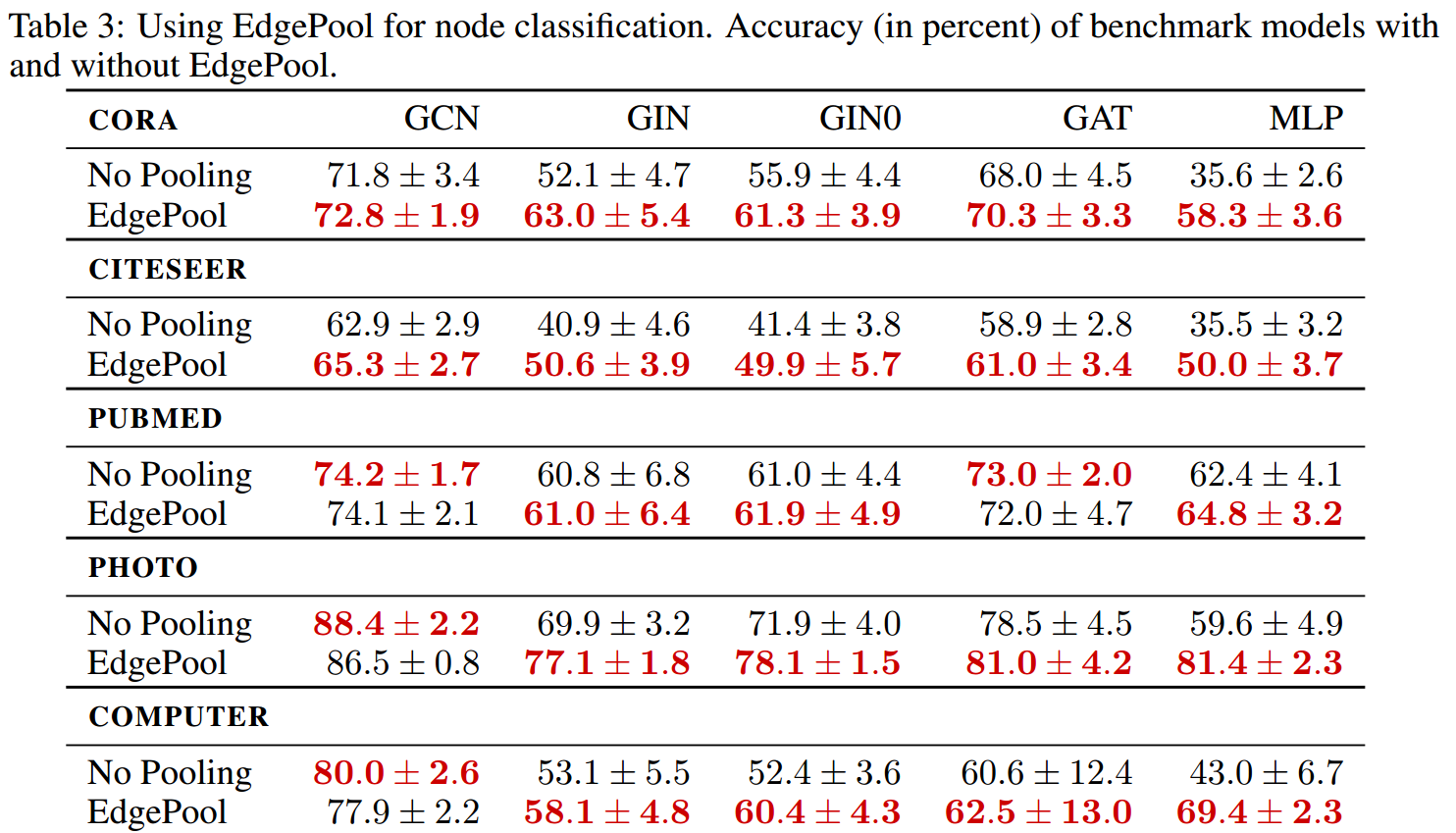
可以看到,使用EdgePool能够普遍地提高node classification的性能。
MLP仅仅通过添加EdgePool来联系节点间的信息,就可以达到媲美GNNs的效果。
可视化
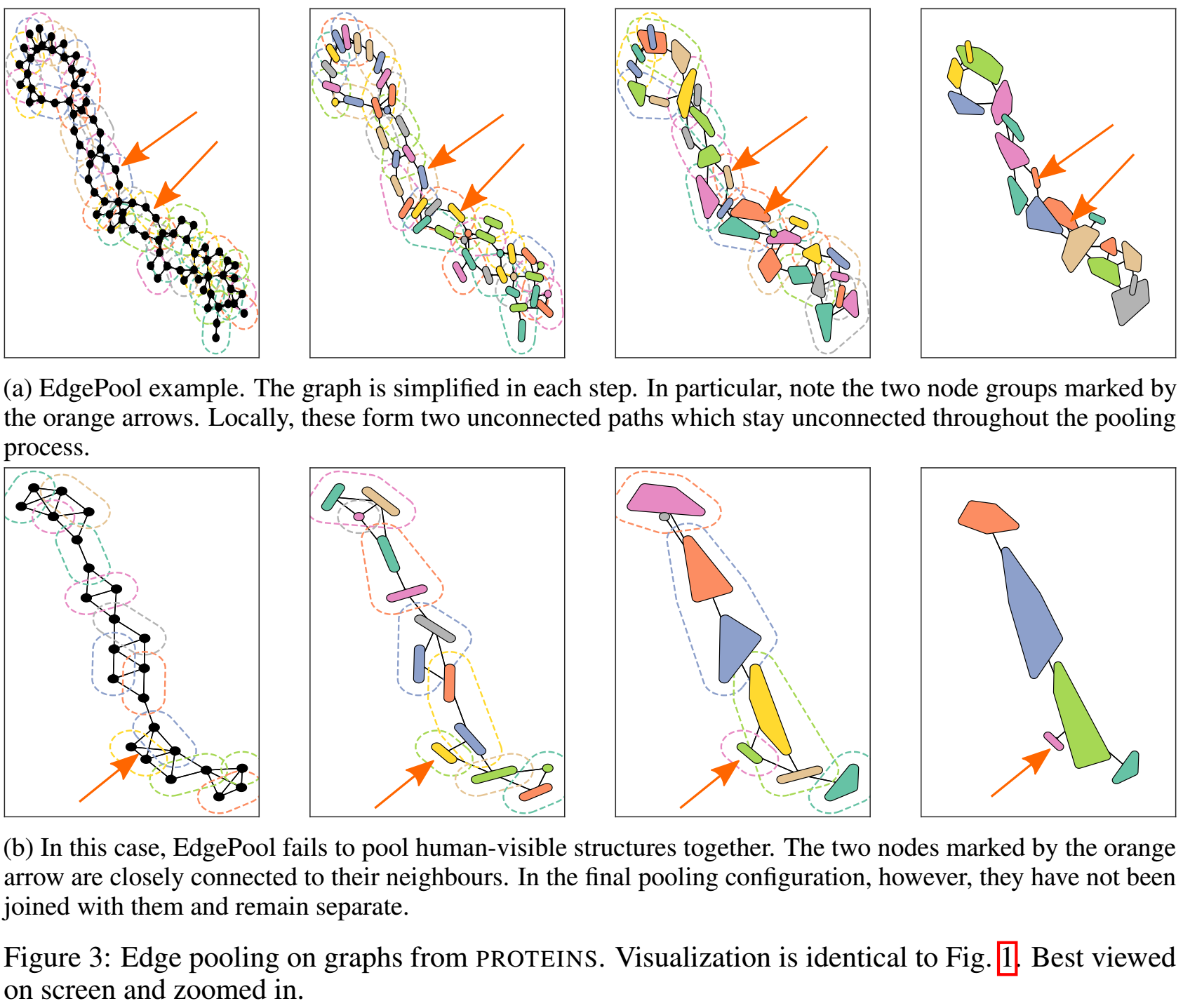
fig1和fig3都是可视化结果。我们发现经过池化后,蛋白质的线性结构依然被保持。但同时在fig3中,我们也发现EdgePool会导致一些反直觉的node poolings。



