Graph U-Nets
- 杂志: Proceedings of Machine Learning Research
- IF: None
- 分区: None
Introduction
CNNs在人工智能领域的成功,促成了类似思想在graph领域的进展(GNNs)。
CNNs在pixel-wise prediction tasks领域取得了一定的进展,比如U-Net【Ronneberger et al., 2015】使用Encoder-Decoder的架构进行。所以是否可以在graph领域将其进行推广是一个非常有趣的问题。
要想进行推广,首先需要解决的就是如何实现在graph上的pooling和unpooling。
本研究提出了gPool和gUnpool operations,从而依靠这两个operations,构建了Graph U-net architecture。其可以进行high-level feature encoding和decoding,用来进行network embedding。
Related Work
这里面介绍了很多方法,如果我比较了解的,就不赘述了。
- GCNs【Kipf & Welling, 2017】
- 【Hamilton et al., 2017】采样固定数量的neighborhoods,从而降低计算量。
- 【Velickovic et al., 2017】将attention mechanism应用于graph。
- 【Schlichtkrull et al., 2018】使用relational GCNs来进行link prediction。
- 还有很多工作进行graph classification tasks。【Duvenaud et al., 2015; Dai et al., 2016; Zhang et al., 2018; Henaff et al., 2015; Bruna et al., 2014】
另外,还有许多研究试图扩展pooling operations到graphs中:
- 【Defferrard et al., 2016】提出使用binary tree来进行graph coarsening。
- 【Simonovsky & Komodakis, 2017】使用的是确定性的graph clustering算法进行pooling。
- 【Ying et al., 2018】使用assignment matrix来进行pooling,assignment可微,从而可以进行end-to-end的training(DiffPool)。
Methods
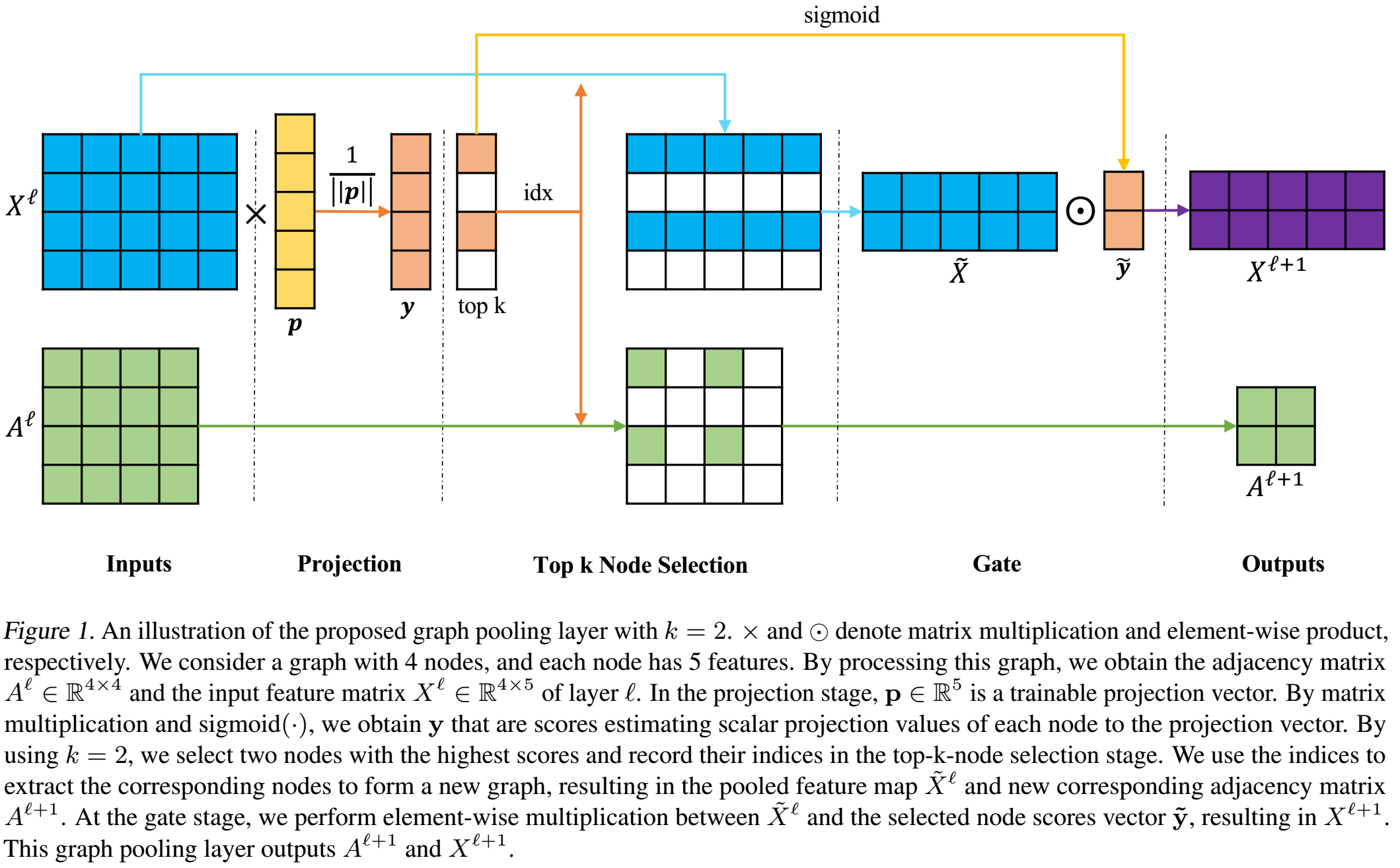
Graph Pooling layer
在第\(l\)层,graph是\(\mathbb{G}\),有\(N\)个节点,每个节点有\(C\)个特征。所以邻接矩阵和feature matrix可以分别表示为\(A^l\)和\(X^l\),\(X^l\)的每一行\(x_i^l\)表示一个节点的特征向量。
主要流程是:
创建一个可训练参数向量\(\mathbf{p}^l\)。
为每个节点计算一个scalar分数:\(\mathbf{y}=X^l\mathbf{p}^l/||\mathbf{p}^l||\)。
选择分数最高的\(k\)个节点:\(idx=rank(\mathbf{y},k)\)。
保留这些节点的特征以及它们的连接关系作为下采样后的图:
\[A^{l+1}=A^l(idx,idx)\quad\text{and}\quad\widetilde{X}^l=X^l(idx,:)\]
根据分数对特征的值进行相应的变换,即排名越靠前的节点的特征越“明显”:
\[\begin{aligned} \widetilde{\mathbf{y}}=sigmoid(\mathbf{y}(idx)) \\ X^{l+1}=\widetilde{X}^l \odot(\widetilde{\mathbf{y}}\mathbf{1}_C^T) \end{aligned}\]
其中\(\mathbf{1}_C\in\mathbb{R}^C\)。
这个操作,也被称为gate operation。其最重要的作用是,使得\(\mathbf{p}\)加入到了整个模型的end-to-end反向传播的训练中。
整个流程图见下图:
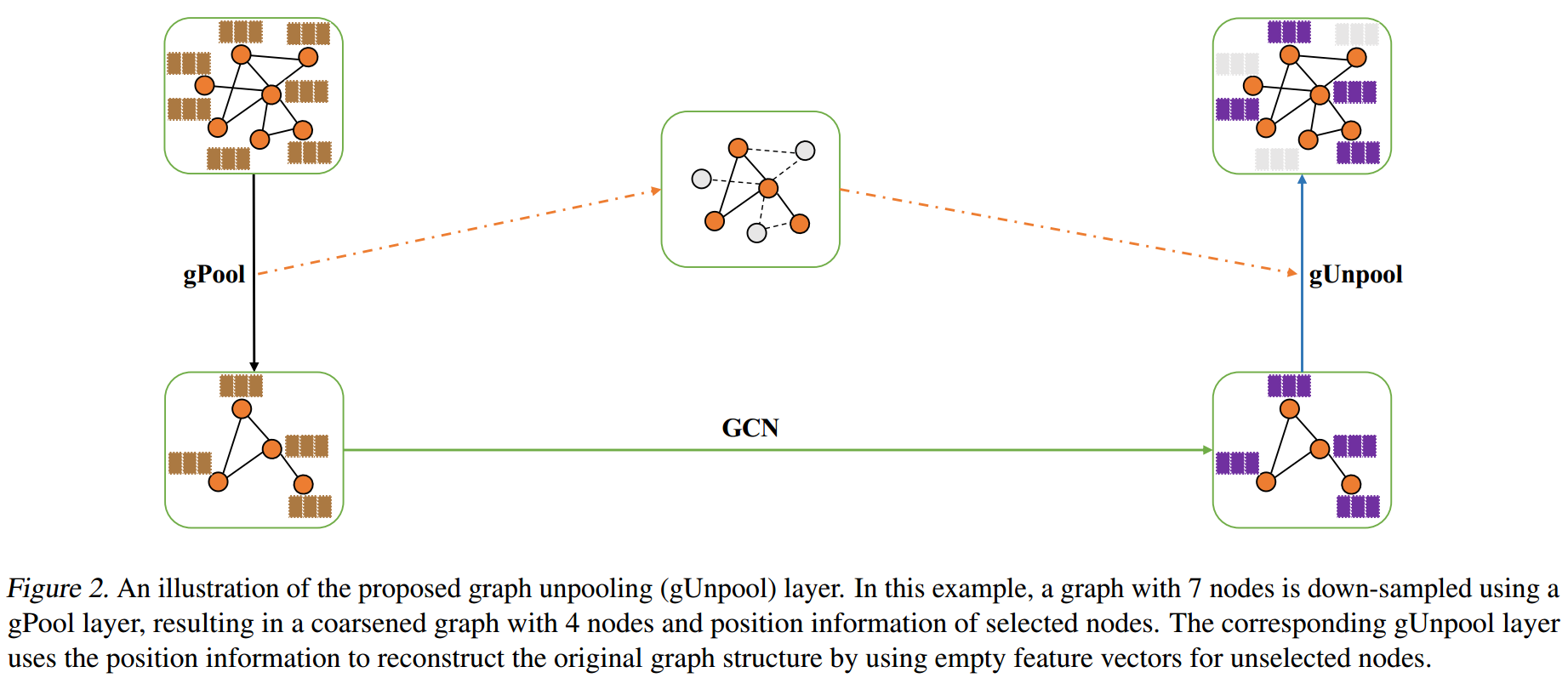
Graph Unpooling layer
这里我们需要进行gPool的时候,把保留的节点的位置记录(这里记录的就是其在\(X\)和\(A\)的行标和列标)。
unpooling后得到的\(A\)就是pooling之前的\(A\)。
unpooling之后的\(X\)的shape和pooling之前的\(X\)shape相同,首先使用0进行填充,然后在我们记录的节点位置上用当前的节点的特征进行填充。
剩下的那些没有填充的节点依然是0。
Graph U-nets
类似计算机视觉中的pixel-prediction工作,我们也可以在graph上使用类似的架构来进行node classification的任务。
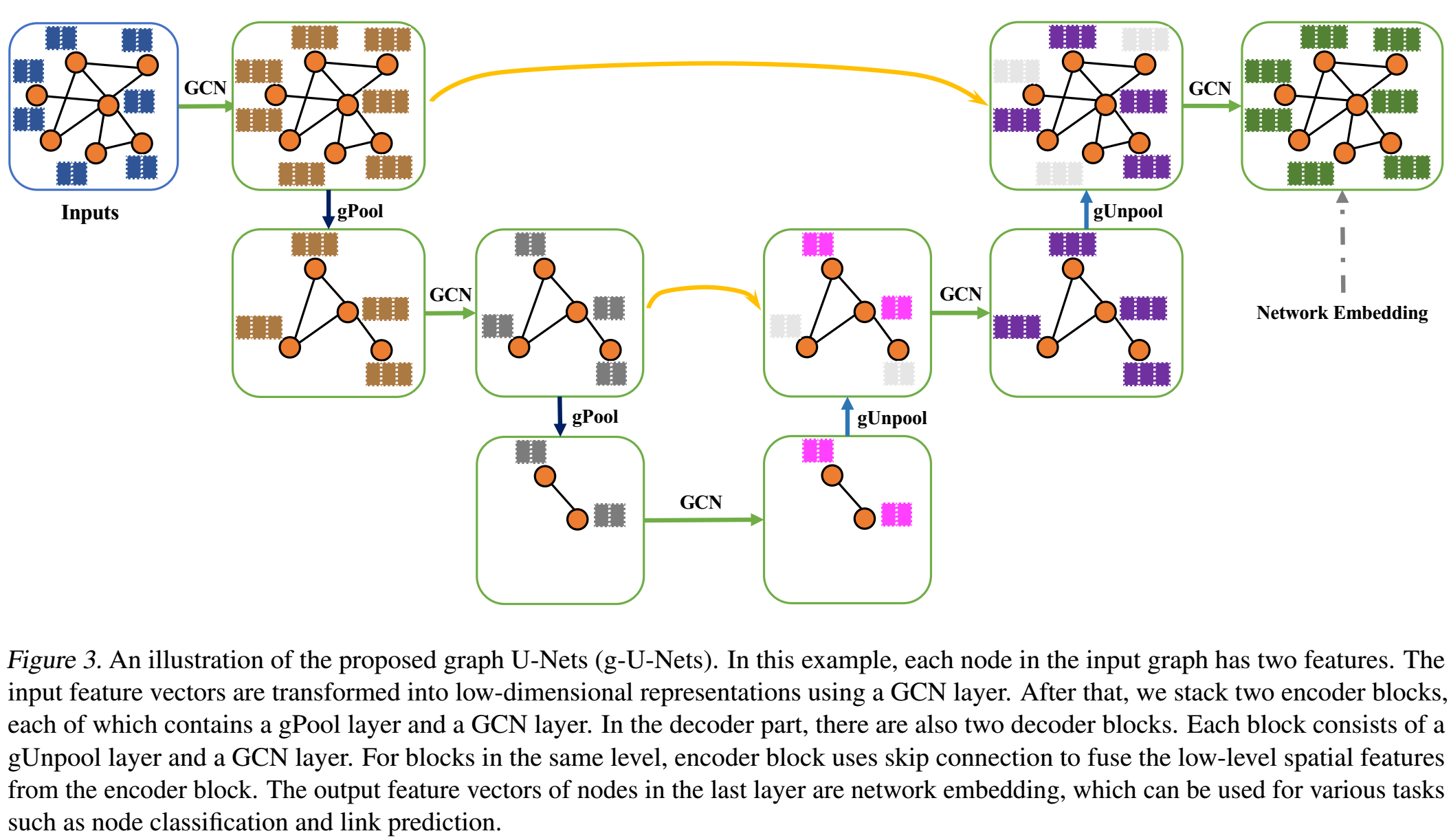
整体的架构可以有上图来描述,其中的skip-connection可以是addition或concatenation。
Graph Connectivity Augmentation via Graph Power
在进行gPool的时候,很有可能导致出现很多的isolated nodes,这可能会影响GNNs的性能。
解决方法是通过一些手段增加一些edges来建立新的联系。这里使用\(k^{th}\) graph power \(\mathbb{G}^k\)来增加graph connectivity。
本研究中使用\(k=2\),则我们只需要改变gPool中\(A^{l+1}\)的计算方式:
\[A^2=A^lA^l,\quad A^{l+1}=A^2(idx,idx)\]
其中\(A^2\)就是2nd graph power,这样会有比原始graph更好的connectivity。
Improved GCN
这里对GCN进行一个小小的改进,即将\(\hat{A}=A+I\)改为\(\hat{A}=A+2I\)。这样在进行feature更新的时候,会更多的考虑节点自身的信息,从而有助于节点分类任务。
Results
这里分别使用node classification tasks和graph classification tasks来验证graph U-nets对transductive learning和inductive learning的作用。
数据集
对于node classification:Cora、Citeseer、Pubmed

这些都是citation networks。20个nodes用于training,500 nodes用于validation,1000 nodes用于testing。
对于graph classification:D&D、PROTEINS、COLLAB

实验设置
transductive learning:
- Encoder:GCN + gPool(2000) + GCN + gPool(1000) + GCN + gPool(500) + GCN + gPool(200) + GCN
- Decoder: (gUnpool + GCN) x 4
- skip connectons: addition
- Predictor: GCN
- Others:identity activaton function【Gao et al., 2018】、L2 regularization(0.001)、Dropout keep rate(for adjacency matrix:0.8,for feature matrix:0.08)
inductive learning:
- follow【Zhang et al., 2018】的设置。
- 使用graph U-nets作为feature extraction。
- 因为graph的大小一直在变,所以这里设置gPool采样的比例为:90%、70%、60%、50%。
- droput keep rate在feature matrix上是0.3。
Performance Study
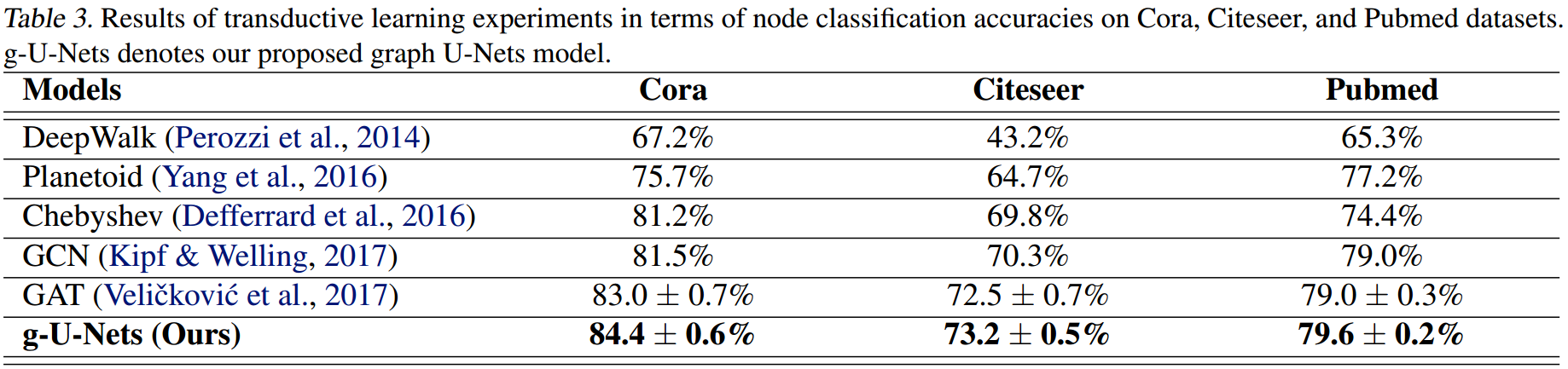
transductive learning:
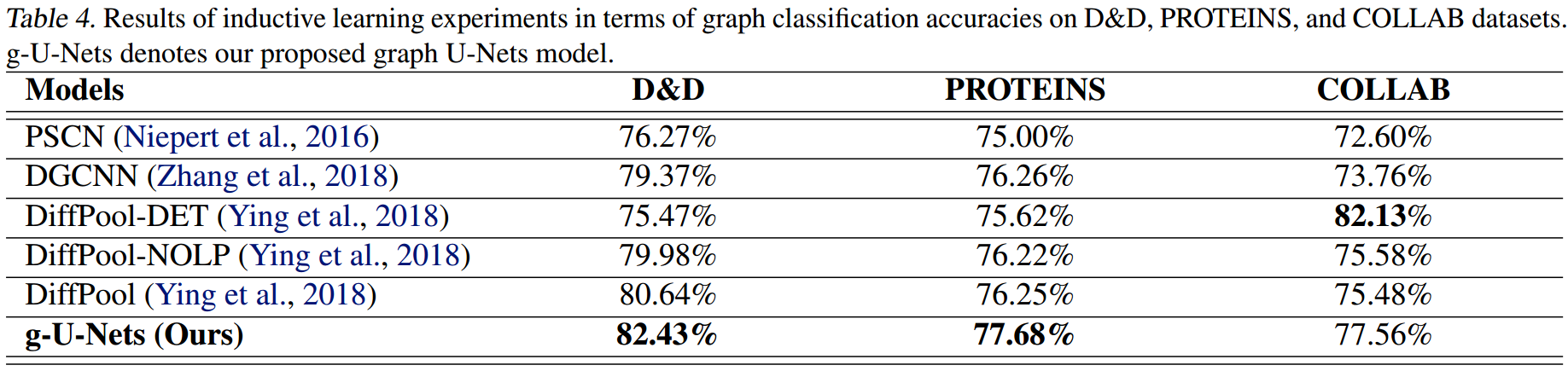
inductive learning:
消融实验
这里,我们将gPool和gUnpool移除,然后看结果的变化:

将graph connectivity augmentation移除,结果:

探索深度对结果的影响:

最佳深度是4。
因为gPool增加了额外的参数,所以这里对其参数增加量和其带来的性能变化进行研究。发现这只带来了参数量0.12%的增加,但带来了2.3%的性能增加,所以这是值得的。




