An Attention-based Graph Neural Network for Heterogeneous Structural Learning
- 杂志: AAAI
- IF: None
- 分区: None
Introduction
graph embedding的方法力图将graph数字化,现存的方法(比如DeepWalk)都是针对同质图(homogeneous graphs),但现实世界中大多数图都是异质的(heterogeneous)。
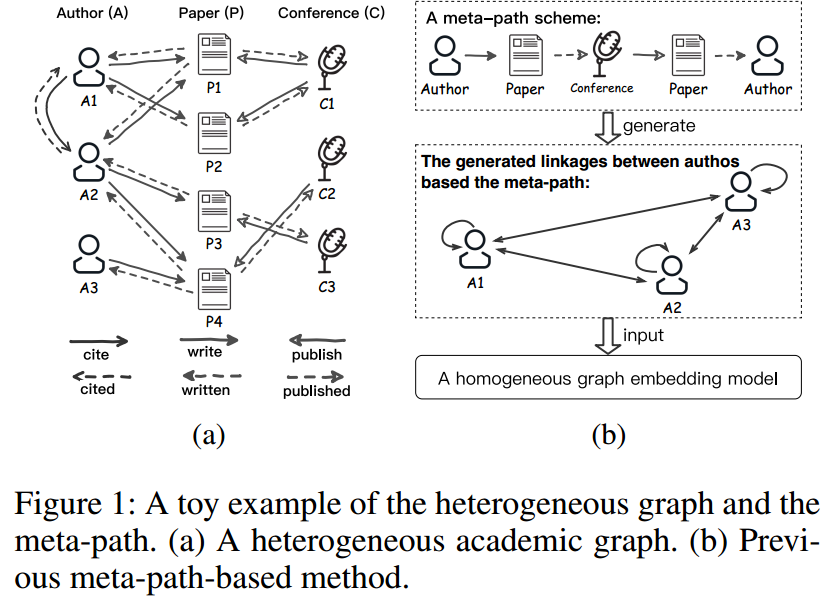
Heterogeneous Information Network(HIN),包含超过两种类型的nodes和edges,并且边是有向的,如下图所示。因此,我们面临以下挑战:
- 如果建模不同类型的nodes?
- 如何保留不同类型edges的语义?比如对于下面的学术网络,author和author之间可能有引用关系,两者也可能是合著了一篇文献的关系。(边和边是不一样的)
当前的大多数研究处理HIN的方式是通过meta-path【Shi et al. 2016】来转换成homogeneous graphs,然后进行进一步的处理(如fig1b所示)。【Dong, Chawla, and Swami 2017, Wang et al. 2019】都是这样处理的。
但我们需要手工来构建合适的meta-path,这带来了下面的问题:
- meta-path的构建依赖于专家,我们也无法穷举求解最好的meta-path。
- 在meta-path上的节点(比如下图所示的paper和conference)会丢失,这可能会导入较差的性能
本研究提出了一种新的方法,其没有使用meta-path,能够学习到graph的包含结构和语义信息的低维表示。
这里我们使用了GNN模型,设计了一种type-aware attention Layer来代替常规的GNN Layer,其可以将不同类型的节点映射到不同的空间中,并且注意到了不同类型edges的影响。
另外,我们开发了一种新的attention scoring function。
我们在3个数据集的实验上验证了我们的想法。
相关工作
以下方法都是依赖于meta-path的:
- metapath2vec 【Dong, Chawla, and Swami 2017】
- HERec【Shi et al. 2018】
- 【Chen and Sun 2017】
- 【Wang et al. 2019】
Methods
首先介绍一下使用的符号:
图 \(\mathcal{G}=(\mathcal{V}, \mathcal{E})\),另外还有节点类型集合和边类型集合 \(\mathcal{A}\)和\(\mathcal{R}\)。对于每个节点,存在一个mapping,将其映射到某个类别上 \(\phi(v)=p\in\mathcal{A},\forall v\in\mathcal{V}\)。对于每条边,我们可以这样表示 \(e=(i,j,r)\in\mathcal{E}\),其中\(i,j\in\mathcal{V},r\in\mathcal{R}\)。所有的边都是有向的,而且边的方向改变可能还伴随着类型的改变(“写”和“被写”是两种类型的relationships),\(e\)的反向边记做\(\widetilde{e}=(j,i,\widetilde{r}),\widetilde{r}\in\mathcal{R}\)。
我们的任务是,对于每个节点\(i\),学习一个低维表示\(\mathbf{h}_i\in\mathbb{R}^{n_{\phi(i)}}\),可以看到,我们希望将不同类型的节点映射到不同的空间中去。
正因为不同处于不同的空间中,所以在利用两个节点来表示不同类型的edge时才会体现出其语义的不同。
以下是整个模型的架构:
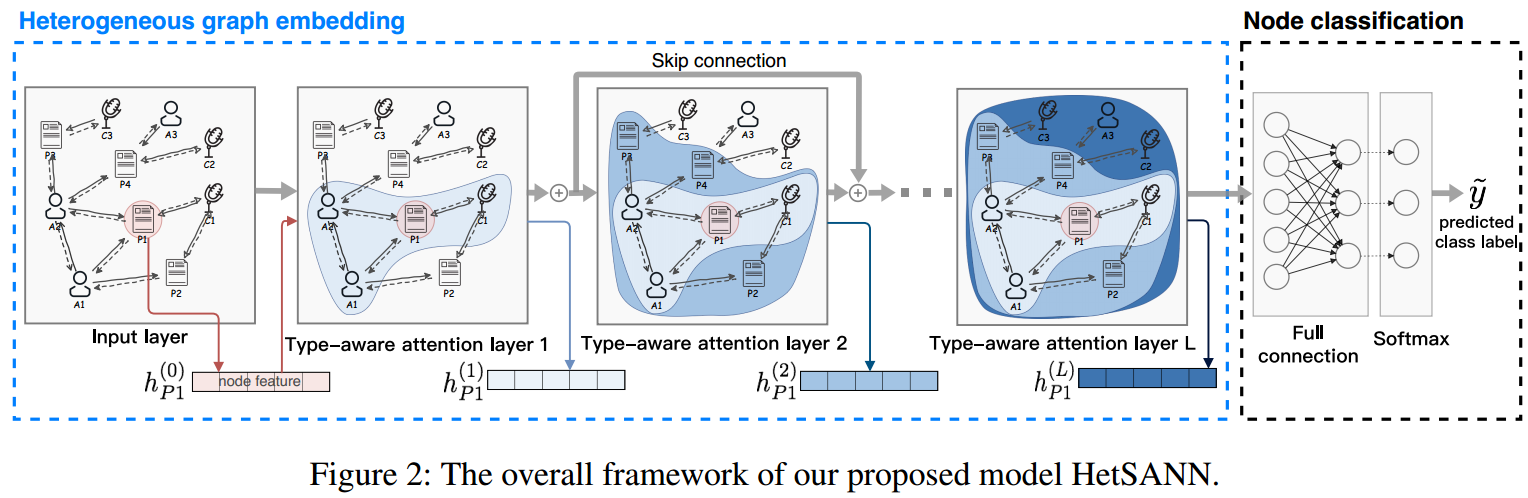
Type-aware Attention Layer (TAL)
下图是TAL的流程示意图:
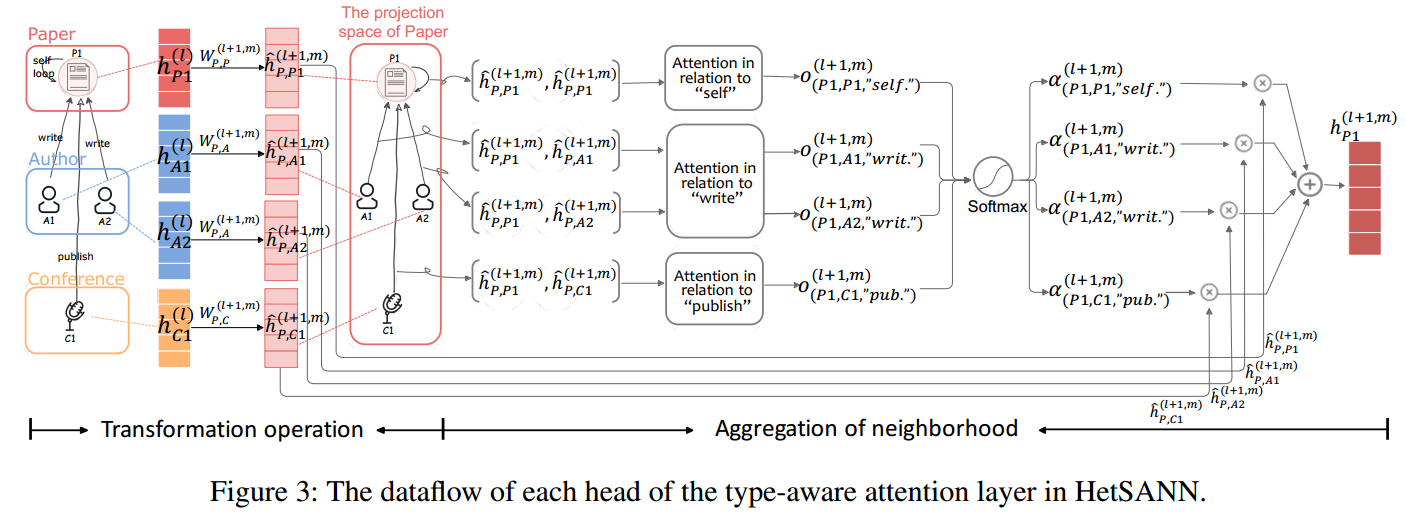
首先为了个节点赋予一个self-loop,表示\(\phi(i)\).
然后设置一个cold start state \(\mathbb{h}_i^{(0)}\in\mathbb{R}^{h_{\phi(i)}^{(0)}}\)作为起始embedding,可以是节点拥有的特征,如果没有特征则使用one-hot向量替代。
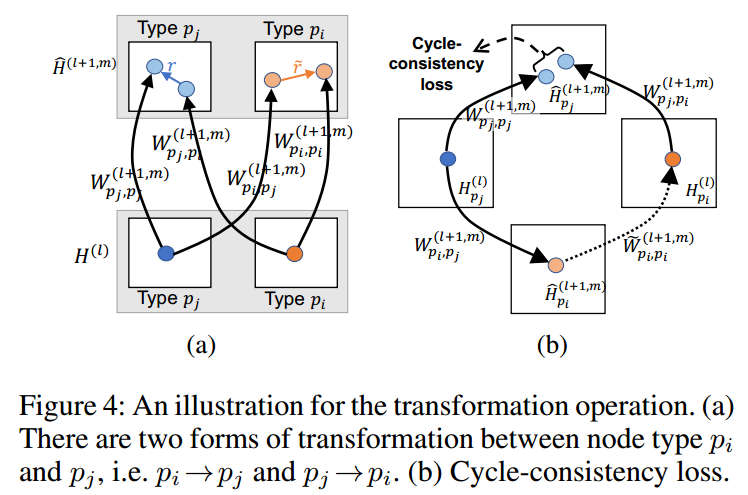
Transformation Operation:对于目标节点\(j\),将其neighborhoods进行一次线性变换,如果是multi-head的话,则需要进行\(m\)次。注意,不同类型的节点间的变化是不同的。
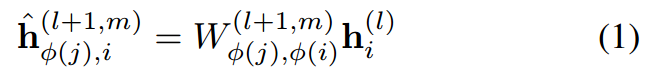
Aggregation of Neighborhood:为了能够保持不同类型边的语义,需要使用\(|\mathcal{R}|\)种attention scoring functions:\(\mathcal{F}^(l+1,m)=\{f_r^{(l_1,m)}|r\in\mathcal{R}\}\)。
对于目标节点\(j\),其邻接边上的attention coefficient可以如下表示:
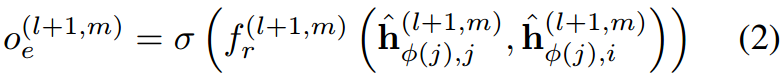
其中\(\sigma\)是激活函数,这里是LeakyRELU。实际上,不同类型的边甚至可以有不同形式的attention scoring functions,这里为了方便,使用相同的函数形式,但拥有不同的参数。
最自然的形式是GAT中的concat product:
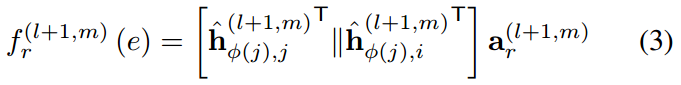
之后,使用softmax来normalize attention coefficient,得到attention scores:
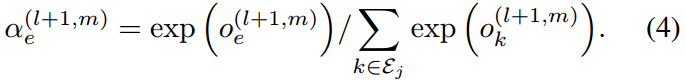
之后我们聚合这些邻接点特征来更新目标节点特征:
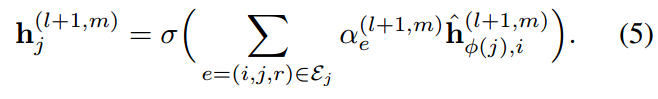
注意到,如果节点\(i\)和\(j\)之间有多种类型的relationships存在,则信息传递过程将会重复多次,使用相应的attention scores。
因为是multi-head的attention机制,所以我们最后还需要将多头得到的特征concat一下:
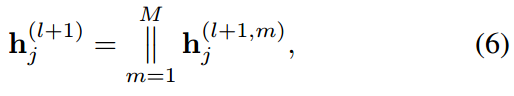
注意到,对于两个author节点,如果使用meta-path,他们是直接相连的。但如果使用HetSANN,因为paper和conference的节点也都要考虑到,所以学习到两个author节点间的信息需要更深的网络。这时候建议使用residual的架构:
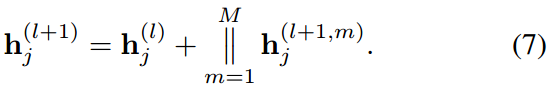
模型训练
我们的任务是一个无监督的任务,但为了能够进行GNNs的学习,这里使用有监督的方式来进行训练。即进行node classification任务,其中标签就是节点的类别。
进一步,我们还可以进行以下3种拓展,来提升训练的效果:
如果我们能够得到多种不同类型的节点标签,可以进行multi-task learning,有助于降低过拟合风险和增强representations的robustness【Baxter 1997】。
上面我们提到了计算attention coefficient的一种方式——concat product,这种计算方式可能是没有效率的。
如果一个author和paper存在关系,则author “写了” paper,paper “被” author写。在concat product中,这两个关系将使用不同的两个functions来计算。但实际上两者在语义上是存在关系的(相反的语义)。
为了能够将这种语义上的相反纳入,可以让计算这两种关系attention coefficients的functions的参数值共享,但互为相反数。所以就有下面的新的计算方式voices-sharing product:
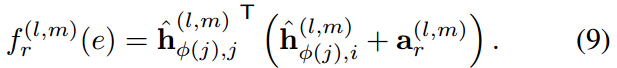
Cycle-consistency Loss。
这个思想来源于NLP的翻译领域的研究(当然,cycleGAN中也用到了)。
对于两个相邻的节点\(i\)和\(j\),我们如公式1所示,会将\(i\)进行一次转换以便能够发送到\(j\)上更新\(j\)的特征(下图b的右上方的实线)(\(j\)的第一次更新)。另外,我们还会在\(j\)上进行一次自我的更新(下图b左上方的实线)(\(j\)的第二次更新)。以\(i\)为目标节点,\(j\)作为其邻接点会更新、发送一次信息到\(i\)上(下图b的左下方的实现)。
\(j\)的第一次更新和第二次更新,都是\(j\)的更新态,两者应该尽可能的相似,我们只要能够找到一个\(i\)的一次“逆更新”,就可以从两条路、同一个起点计算\(j\)的更新态,从而构建一个cycle-consistency loss。这个“逆更新”理论上是\(i\)到\(i\)自更新的权重矩阵的逆,但这里为了计算量的考虑,使用一个可训练的参数来拟合它,从而我们得到了这个loss:

Results
比较的模型有:
.M、.R、.V分别表示多任务学习、voice-sharing product和cycle-consistency loss。如果是.M.R.V则表示这3个提升都用上了。
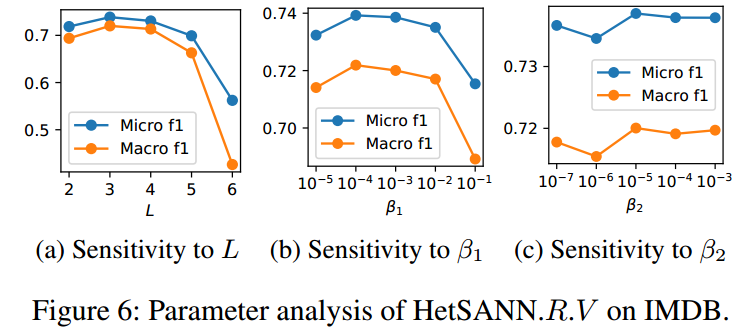
使用的模型是3-layer的HetSANN,每个layer有8个attention heads,每个head的输出维度都是8。adam(IMDB lr=0.001,其他 lr=0.0005),每一层间的dropout rate是0.6。cycle-consistency loss的系数 \(\beta_1=10^{-3},\beta_2=10^{-5}\)。
比较的baseline在下面的表格中可以看到。
使用的数据集的信息:

评价指标:train:valid:test=0.8:0.1:0.1,使用valid上最好的用来在test上进行验证。使用的指标是micro f1和macro f1。每个重复10次。
整体结果如下表所示:
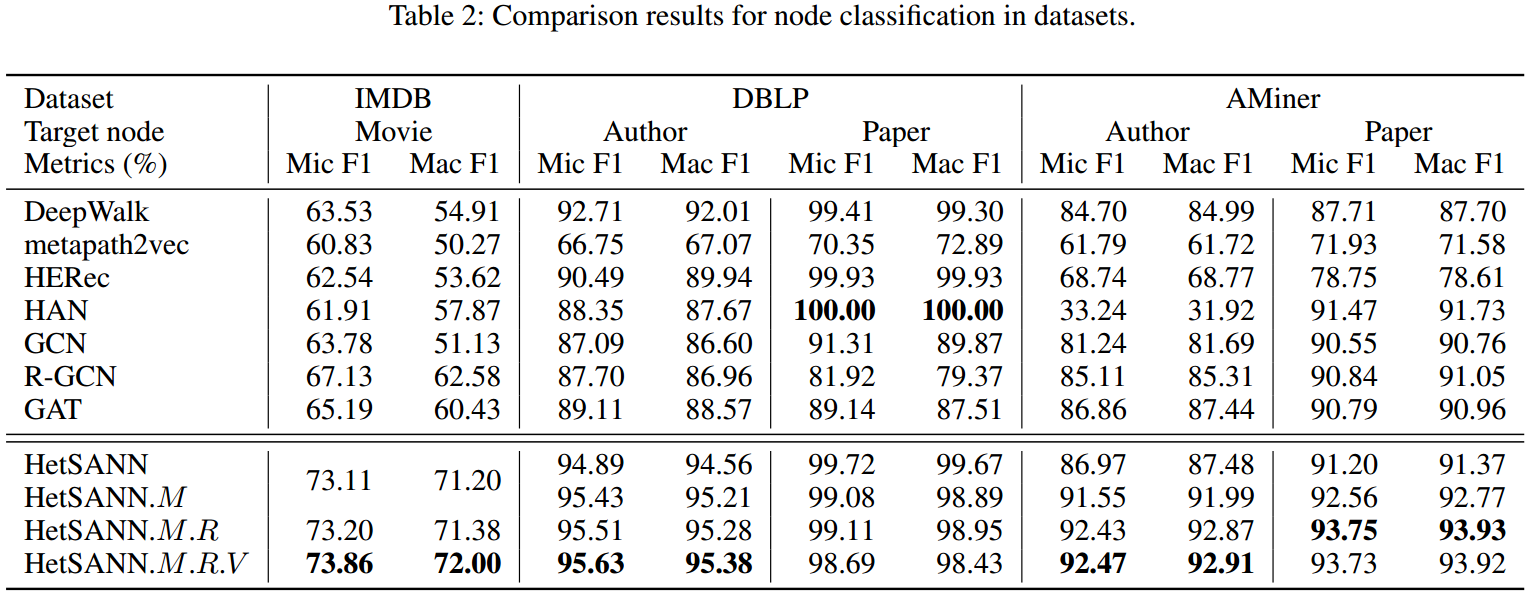
- 这3种提升都对模型有所帮助,.V提供的提升较小。
- HetSANN除了一个任务外,其他任务的表现都是最好的。
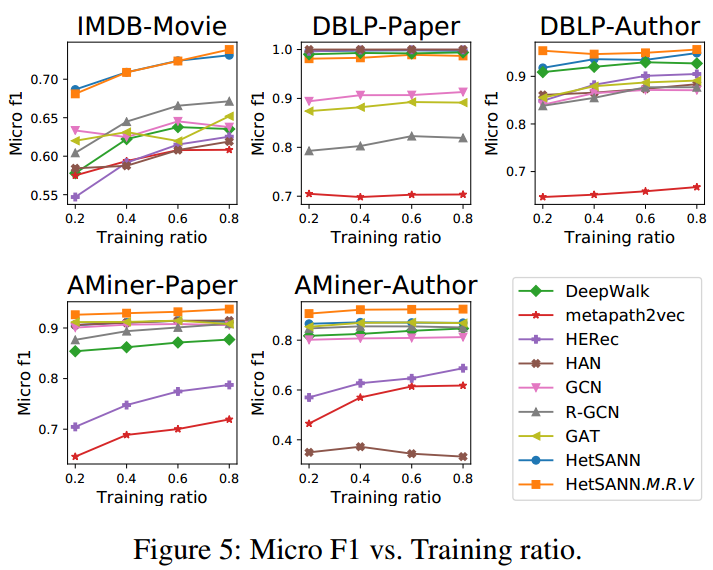
下图表示了使用不同比例的数据作为训练集的效果:
进一步,进行了一些超参数的敏感度分析:
Conclusion
Questions
可以看做是GAT的加强版,只是对不同类型的nodes、edges使用不同的参数。



