Point-GNN: Graph Neural Network for 3D Object Detection in a Point Cloud
- 杂志: CVPR
- IF: None
- 分区: None
Introduction
点云数据是理解3D环境的一个重要的数据形式,但其稀疏、不规则的特性使得其无法以常规的手段(如CNN)处理它。(或者会耗费大量的计算)
最近的在NN方面的突破【3,22】使得开始可以处理点云数据,但这些方法大多需要进行迭代的sample和group来得到point set representation,计算非常昂贵。
最近的3D detection技术还会混合grid和set的技术【10,21,16】,但这些技术也显示出其不足。
在本研究中,我们使用graph来对点云进行表示,并设计了一个新的GNN称为Point-GNN来进行目标检测。为了能够降低GNN的translation variance,这里使用了一个auto-registration的机制。另外还设计了box merging和scoring operation从多个点整合detection结果。
【15,9,2,17】已经验证了使用GNN进行分类和分割点云的能力,但使用GNN进行3D目标检测还是比较少的。
相关工作
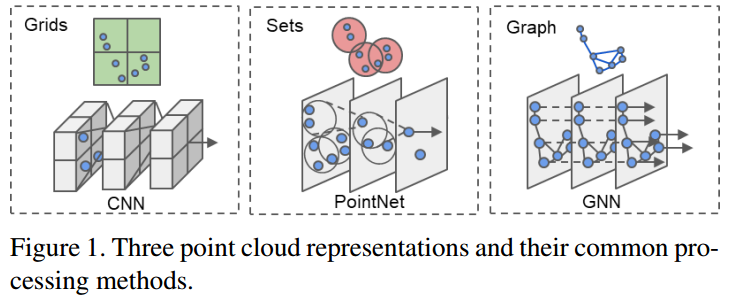
grids点云
将点云数据转换成规则的grid数据,然后使用CNN。
- 【20】将点云数据转换到2D bird‘s eye view(BEV),然后使用2DCNN进行目标检测。
- 【4】将点云数据转换到BEV和Front View(FV)然后使用2DCNN。
- 【23】将点云转换成3D voxels数据,然后使用3DCNN。但这计算花费太高了。
- 【19】继承上面的研究,使用sparse convolution减小计算花费。
set点云
- 【3,22】(PointNet、DeepSet)对每个点使用MLP来得到point feature,然后使用average或max来得到global feature。
- 【14】进一步提出对point features进行层次的聚合以提取局部信息。
虽然以上的算法避免了映射成grids,但sampling和grouping也增加了另外的计算开销。
大多数目标检测的算法都将以上的NN当做整个pipeline的一部分:
- 【13】从camera images中生成object proposals,然后使用【14】的算法分割点云并预测bounding box。
- 【16】直接使用【14】作为backbone来生成bounding box,然后使用second-stage point network来refine bounding box。
- 【23,19,10,21】都使用【3】来从local point sets中提取特征。
graph点云
相比于基于set的操作,graph能够保证通过edge的连接来实现更复杂的操作,而且也不需要进行sampling和grouping。
- 【15】使用recurrent GNN在RGBD数据上进行语义分割。
- 【9】将点云划分成简单的几何图形
- 【2,17】直接使用GNN对点云进行分类
但使用GNN对点云进行目标检测的还非常少。
Methods
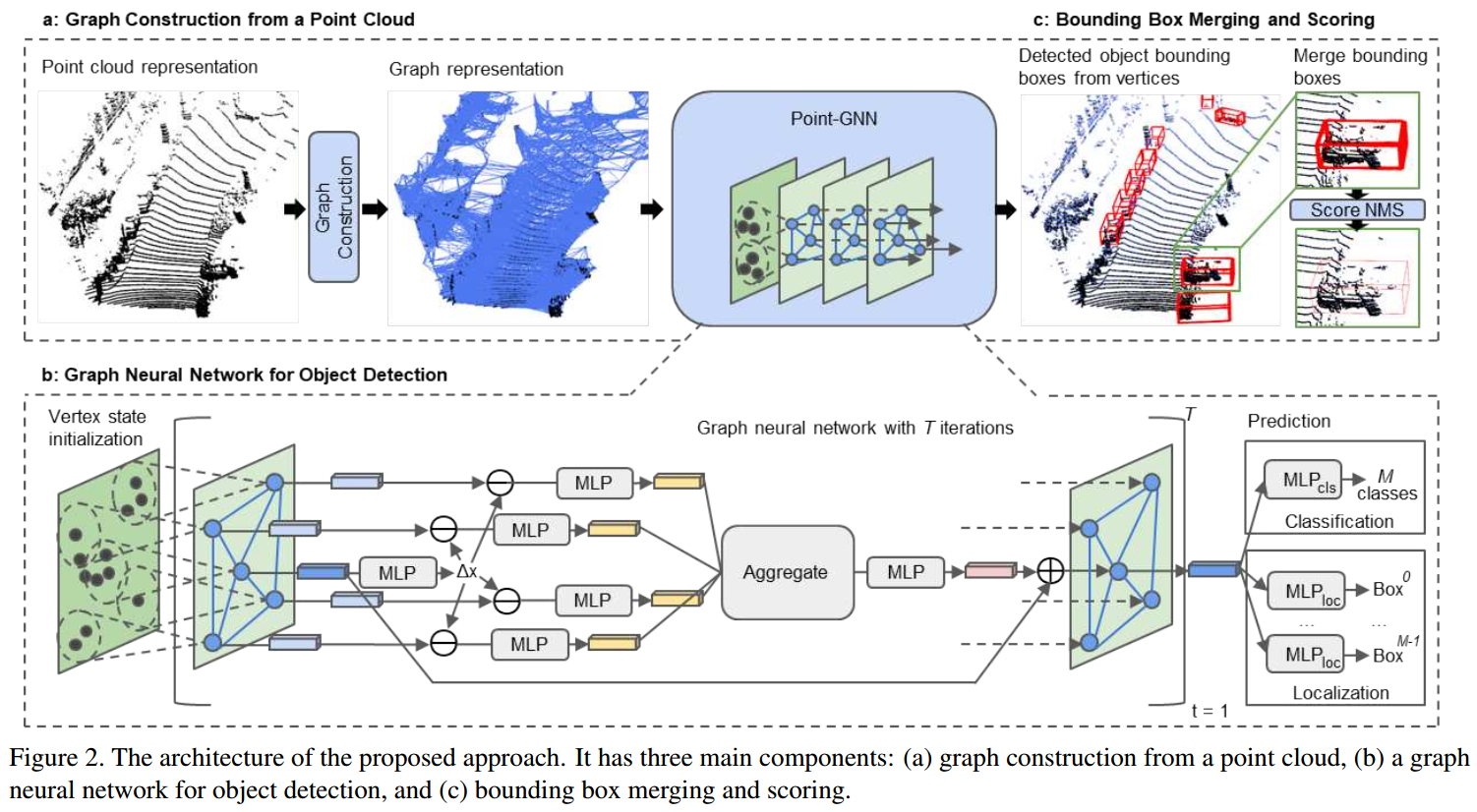
构建graph
点云\(P=\{p_1,\dots,p_N\}\),其中\(p_i=(x_i,s_i)\),\(x_i\in\mathbb{R}^3\)是点的3D坐标,\(s_i\in\mathbb{R}^k\)是点的k维特征,表征点的属性(比如反射的激光强度和编码等)。
我们定义一个graph \(G=(P,E)\),其中
\[E=\{(p_i,p_j)|||x_i-x_j||_2\lt r\}\]
\(r\)是一个固定的半径,即认为如果两个点距离小于此,则认为两者相连。
正常来说,一个点云会有数万个点,如果全使用,会导致较高的计算负担。所以这里使用voxel downsample点云(follow 【10,23】,使用MLP和Max func来提取特征),之后再建立graph。
带有Auto-Registration机制的GNN
GNN的更新机制为:
\[ \begin{aligned} v_i^{t+1}&=g^t(\rho(\{e_{ij}^t|(i,j)\in E\}), v_i^t) \\ e_{ij}^t&=f^t(v_i^t,v_j^t) \end{aligned} \]
这个表示可能比massage passing的一般表示更加general一些,但大体上,两者可以算作是一样的东西。比如我们把\(e_{ij}\)的内容写到前一个式子中,则整个公式将和massage passing一致。
本研究使用的GNN的更新机制为:
\[ s_i^{t+1}=g^t(\rho(\{f^t(x_j-x_i,s_j^t)\}), s_i^t) \]
即我们不光考虑邻接点的特征,而且还要考虑邻接点相对于更新的节点的相对位置。使用相对位置使得我们在全局上保持了一个平移不变性,但在局部依然有一定的问题。如果目标节点的坐标出现一个小小的移动,则其邻接点相对于其的坐标都会发生变化,尽管这可能与之前并没有什么不同。
为了解决上面的问题,这里认为有部分信息储存在其属性特征中,所以我们需要进一步利用这些特征来校正相对位置,所以使用下面的auto-registration机制:
\[ \begin{aligned} \Delta x_i^t&=h^t(s_i^t) \\ s_i^{t+1}&=g^t(\rho(\{f(x_j-x_i+\Delta x_i^t)\}), s_i^t) \end{aligned} \]
如果fig2中所示,这里的\(f^t,g^t,h^t\)都使用MLP来拟合,而\(\rho\)则使用Max,\(g^t\)上加上一个residual link。
当经过\(T\)层的迭代计算后,使用两个MLP基于节点特征分别预测类别和bounding box。
损失函数
作为目标检测,损失函数包括两个部分,即分类部分和bounding box regression的部分。
classification,对于每个点,其都会被分配一个类别:如果其存在在某一类的bounding box中,则其属于此类;如果其不属于任何物体的bounding box中,则属于background类。
然后对每个点使用交叉熵损失即可。
bounding box regression。
对于每个点,我们需要预测7个值:其中3个表示bounding box的中心节点,另外3个表示bounding box的长宽高,还有一个表示box的yaw angle(偏航角)。
当然,这个我们回归的是相对值:
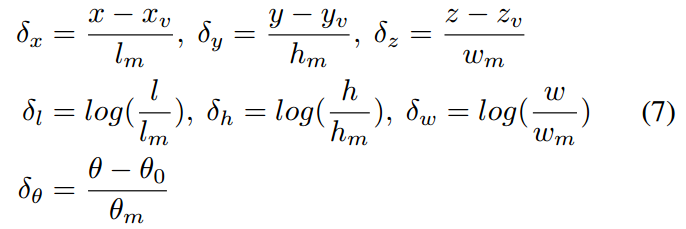
如果该点在box内,则我们计算ground truth和其预测的Huber loss【7】,否则为0。所以其公式可以表示为:
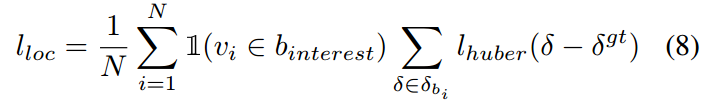
最后,我们在加上权重项的L1正则化以防止over-fitting:
\[l_{total}=\alpha l_{cls} + \beta l_{loc} + \gamma l_{reg}\]
Box Merging and scoring
因为会有许多的点在同一个bounding box中,所以会导致有大量重合的bounding box prediction,所以我们需要使用NMS来选择出其中得分最大的那个,而去抑制其他的boxes。
但使用分类的分数并不足以反应定位的质量,比如被遮挡的物体,其分类的分数最高的框可能并不是最正确的那个框。所以这里使用一种新的算法来替代NMS:
计算多个重叠框的median作为最终的结果(boxes),而不是分类概率最大的那个。
boxes的confidence score由最终结果和重叠框的IoU和重叠因子计算而来,重叠因子的算法为:
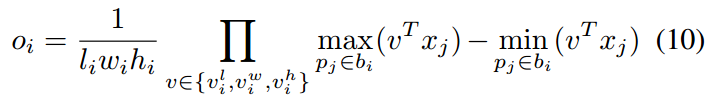

Results
数据集:
KITTI【6】,7481 training samples,7518 testing samples,每个都有point cloud和camera image。
评价指标是Car、Pedestrian(行人)和Cyclist(自行车)的AP,根据【10,23,19,21】的惯例,为Car训练一个net,为Pedestrian和Cyclist训练一个net。
实现细节
- T=3(GNN层数)
- 训练时每个点的度最大为256,预测时使用所有的edges
- auto-registration的MLP为(64,3)
- 分类的MLP为(64,类别数)
- 定位的MLP为(64,64,7)
更详细的见原文
数据增强
- global rotation(\(\mathcal{N}(0,\pi/8)\))
- global flipping(x轴,\(p=0.5\))
- box translation and vertex jitter(\(\Delta x\sim\mathcal{N}(0,3),\Delta y=0,\Delta z\sim\mathcal{N}(0,3)\))
结果
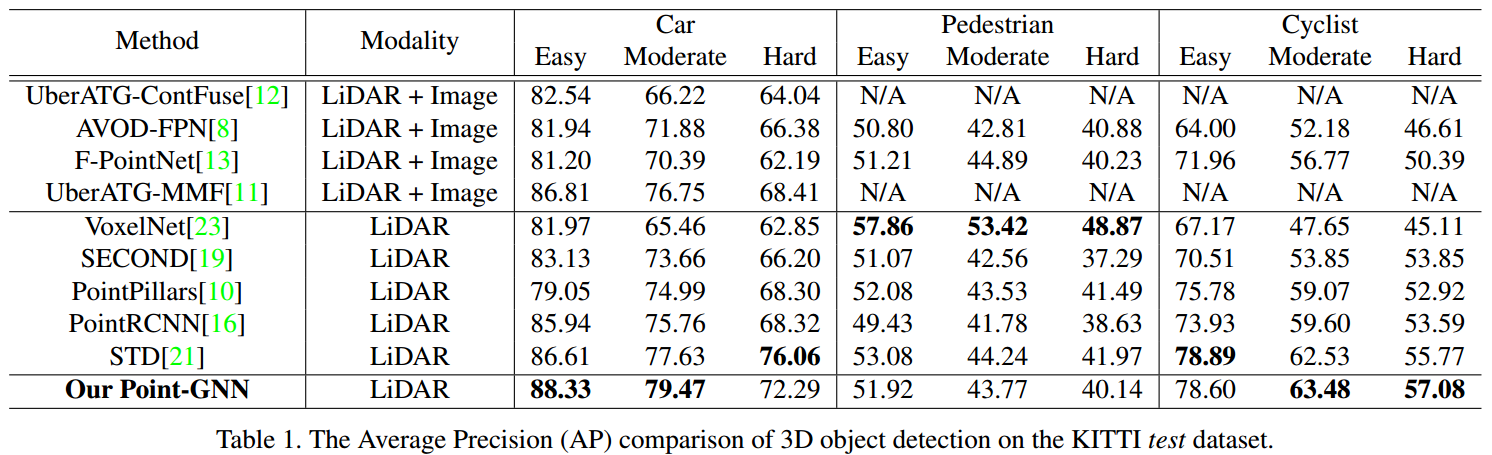
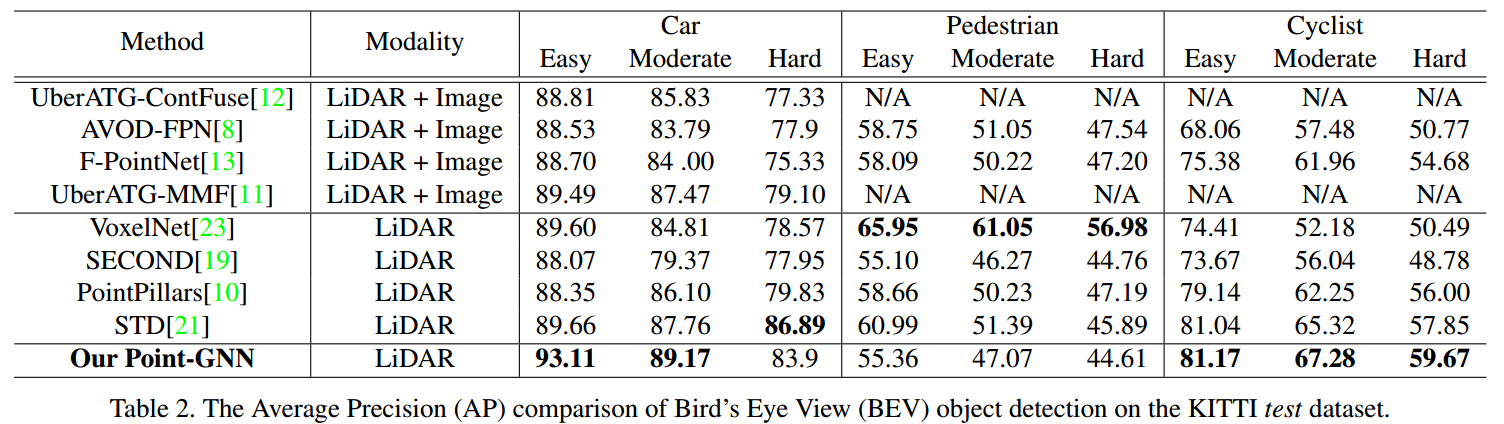
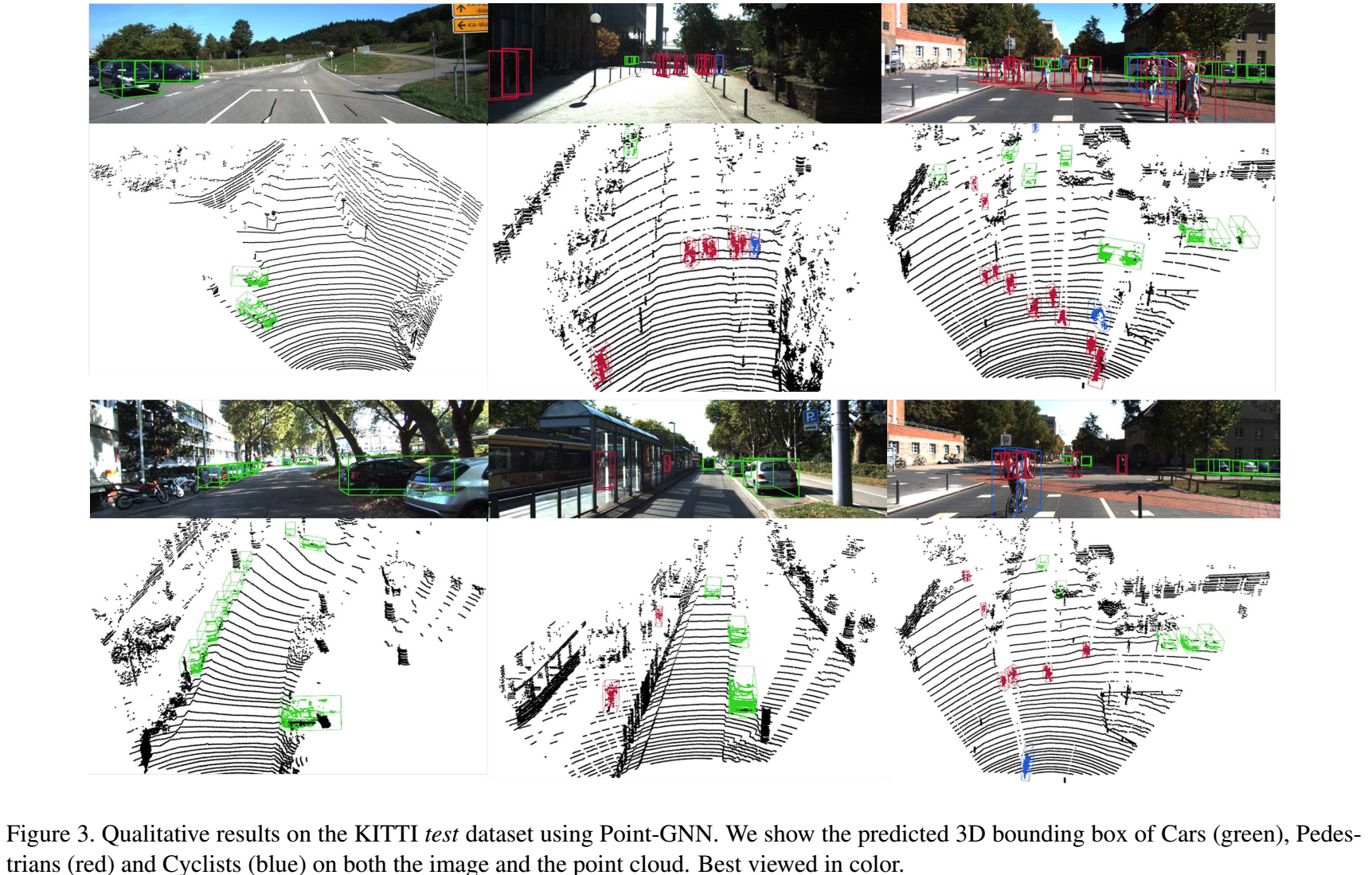
消融实验
将train set分割成train(3712)和valid(3769),重点只关注Car这个类别。
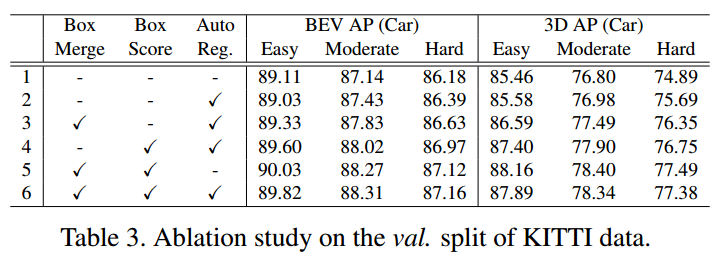
从上面的表中可以看出,这三种机制不同程度的提高了模型的性能。
另外,我们进一步可视化了auto-registration机制所带来的影响:
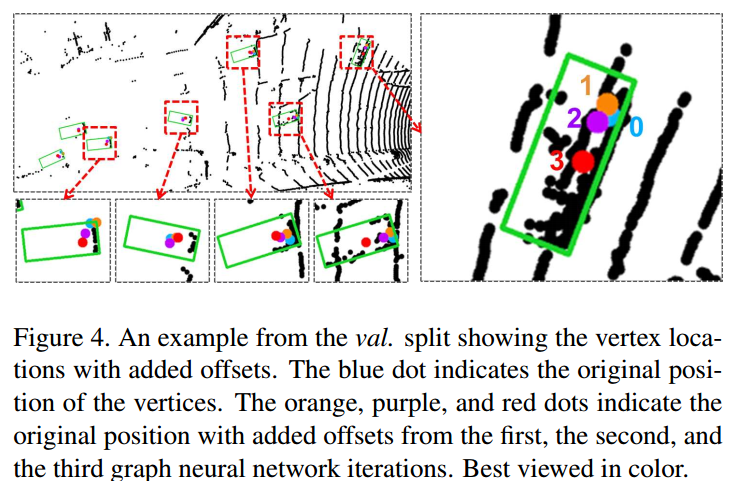
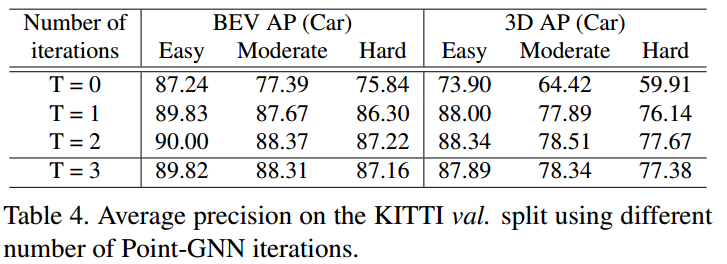
本研究也对使用的GNNs的层数进行了研究:
另外,还探索了scaling line不同所带来的影响,scaling line越多,则点云越密集,自然计算量越大。这里使用k-means来模拟scaling line的减少,结果如下所示: