DeepGCNs: Can GCNs Go as Deep as CNNs?
- 杂志: None
- IF: None
- 分区: None
Introduction
因为non-Euclidean数据的大量增加以及CNNs在上面的不良表现,GCNs收到了更大的关注;
GCNs的应用:社会网络关系预测【36】、建模蛋白质【54,40】、提高推荐系统的预测准确性【24,50】,有效分割点云【42】;
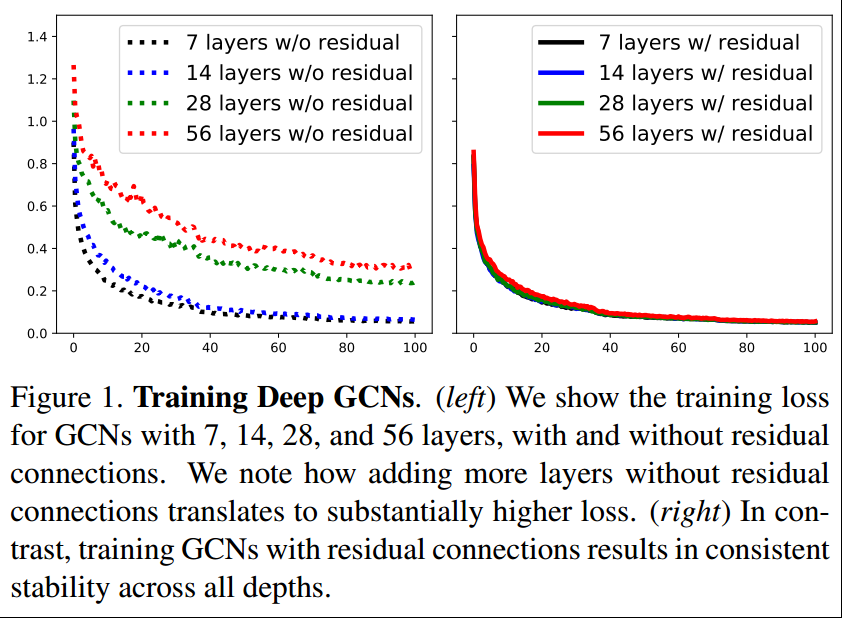
CNNs成功的一个重要因素是可以训练非常深的CNNs,但这还无法应用于GCN【19,43,53】,这会引起vanishing gradient problem,即反向传播会导致过度平滑,导致graph上学习到的特征区域相同的值【19】,所以大多数的GCNs不会超过4层;
梯度消失在CNNs中也出现过,但ResNet、DenseNet等的提出解决了这些问题;而至于多层多pooling导致的spatial信息丢失则通过Dilated Conv【51】得到解决;
本研究希望将上述3个想法应用到GCNs领域,来解决GCNs的问题。将得到的非常深的GCNs(56层)应用于point cloud semantic segmentation(S3DIS),得到了非常大的提升(3.7%);
贡献:
- 将residualconnections,dilated conv整合到了GCNs中;
- 在point cloud data上显示了这个深度GCNs的效果;
相关工作
GCNs的应用:上面提到了一些,这里再补充一些
自然语言处理【2,23】;
GCNs在图像的应用:进行分割的时候,一般对象间的关系使用graph来描述,可以用来预测场景中各个对象间的关系【30,44,48,20】,或者通过各个对象间的关系生成一张图【17】;
在视频中识别人体的关节【47,16】;
GCNs处理点云数据,【35,9,3,22,5,28,32,37】试图将点云数据表示成graph,而【27,29,8,14,49】则试图直接处理点云数据;
这里点云数据就是使用三维坐标描述的点集合,可以利用最近邻、分块等技术来构建点和点之间的graph。
EdgeConv【42】就是使用GCNs来处理点云,使用距离在每一层动态地计算每个点的最近邻,显示了GCNs处理点云数据的能力(本研究正是在【42】的基础上进行的);
Deeper GCNs:
【18】表示在超过3层的时候,GCNs在半监督节点分类任务上会变得不好;
【26】提出了Column Network,最佳分类效果是10层;
【31】使用了Highway GCN应用于社交媒体地理位置建模,但发现6层的时候效果最好;
【46】提出了Jump Knowledge Network进行表示学习,也只能到6层;
【19】研究了GCNs的深度问题,发现深度的GCNs会导致over-smoothing问题,导致每个连接的点内的特征会趋向于相同的值;
【43,53】等也显示出堆叠过多的GCN layers会导致复杂的梯度和梯度消失等问题;
这里特别提一下Dilated conv,其通过提高感受野的方法,使得卷积得到的分辨率较低但没有使用pooling,防止了信息的丢失;
Methods
图上的表示学习
这里使用的理论框架是:
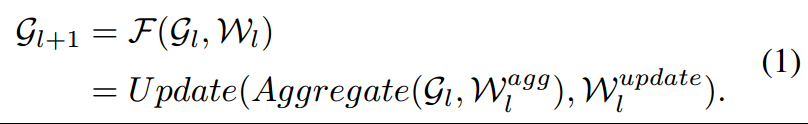
其中aggregate过程是将节点及其邻接点的信息结合,update则是将得到的信息使用非线性函数计算新的节点表示。
aggregate可以是mean【18】、max-pooling【27,10,42】、attention【39】、LSTM【25】;
Update可以是multi-layer perception【10,7】、gated network【21】等;
下面是更加具体的公式:
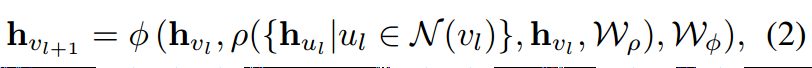
其中\(\rho\)是aggregate函数,\(\phi\)是update。
在本研究中,使用的aggregate是max-pooling of difference,因为没有学习参数:
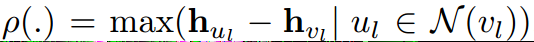
使用的update是一个MLP,使用BN和relu,其输入是原始节点信息\(\mathbf{h}_{vl}\)和上面的\(\rho\)函数得到的值。
动态边
大多是GCNs使用的都是固定的graph,而只更新节点特征,而最近的一些研究可以在每一层动态的改变网络的连接模式,学习到更多的特征;
ECC【34】使用dynamic edge-conditional filters去学习一个edge-specific weight matrix,EdgeConv【42】则使用最近邻来建立一个graph进行图卷积操作,Graph-Convolution GAN【38】也是这个思想;
本研究发现在GCNs中动态地改变邻接点可以有效缓解over-smoothing的问题,并有更大的感受野,所以在本研究中,通过Dilated k-NN函数在每一层重新计算节点间的边,只有Dilated k-NN将在下面进行介绍。
GCNs上的residual link
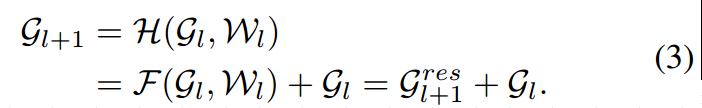
特征是vertex-wise addition的。
GCNs上的dense link
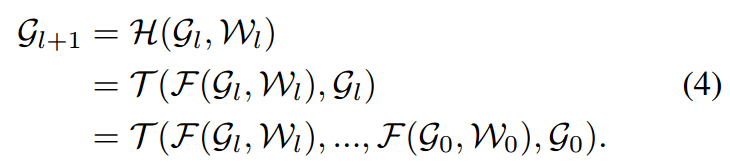
其中操作\(\mathcal{T}\)表示vertex-wise concatenation操作,因为上一层也会将上上一层concat,所以在第\(l\)层就是将之前所有层的结果都concat到了一起; 注意到,不然输入是多少,\(\mathcal{F}\)函数在每个节点上的输出都是\(D\)维度的,所以在第\(l+1\)层上节点特征的维度是\(D_0+D×(l+1)\)。
GCNs的Dilated聚合
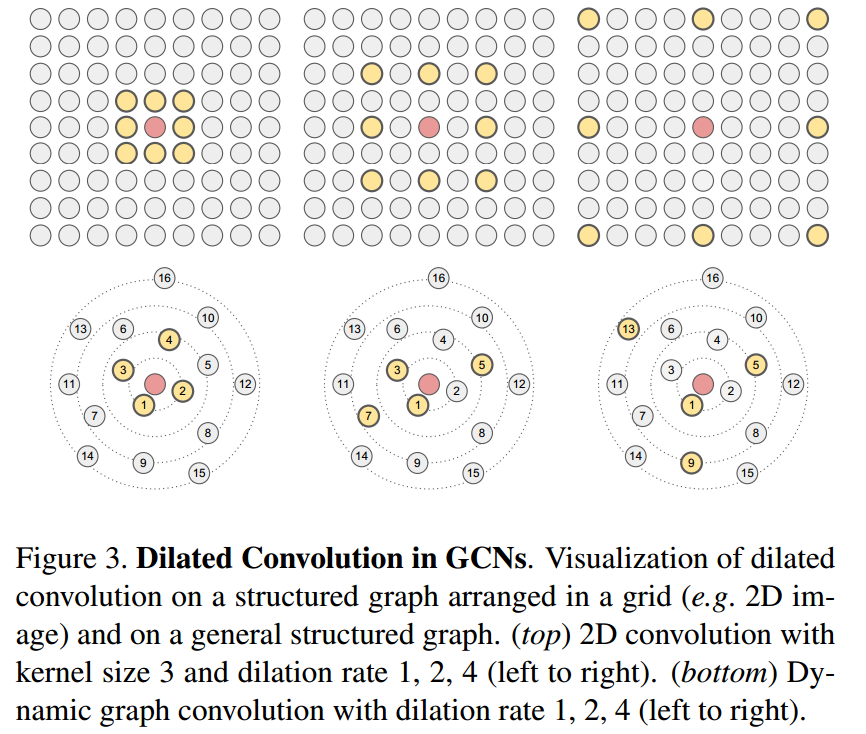
Dilated wavelet conv来自于小波领域【12,33】,为了避免pooling带来的信息损失,【51】提升了dilated conv来解决,因为其没有分辨率的损失但提高了感受野,在图像分割等领域应用比较多;
因为一般conv filters都会一次用很多个做,所以第一个conv filter没有识别到的信息可以用第二个conv filter来识别,但如果做了pooling,那损失了的信息这些filters是都看不到的
本研究提出了Dilated k-NN来在每一层寻找dilated neighbors并构建Dilated Graph,
首先通过当前空间中的距离(本研究使用的是l2)来定义每个节点的neighbors;
如果定义的dilated rate是\(d\),考虑的邻居数量是\(k\),则先对每一个节点找到和其最近的\(k\times d\)个邻居,并排序 \((u_1,u_2,\dots,u_{k\times d})\)。
然后每隔\(d\)个邻居选择一个出来,得到的邻居集合是
\[\mathcal{N}^{(d)}(v)=\{u_1,u_{1+d},u_{1+2d},\dots,u_{1+(k+1)d}\}\]
然后上述节点和v节点有边相连,边的方向是从v指向这些邻居节点;
对所有的节点进行上述操作,得到一张图;
为了增加泛化能力,这里使用的是stochastic dilation:
training:即用高概率\(1-\epsilon\)来实施上面叙述的dilated操作,而比较小概率对于一些节点使用随机dilated操作(从\(k\times d\)个邻居中随机采样\(k\)个邻居);
testing:没有随机性了,就是使用上面提到的确定性的dilated策略;
Results
实验设置
使用的图是通过上面叙述的dilated k-NN来得到的,并且是在特征空间中创建的;
预测的是每个点的类别;
评价指标是overall acc(OA)和mean intersection over union(mIoU)在所有类别上,其中IoU计算为 \(TP/(TP+T-P)\)。
其中\(TP\)是true positive points,\(P\)是预测positive的points,\(T\)是真实positive的points;
实现细节
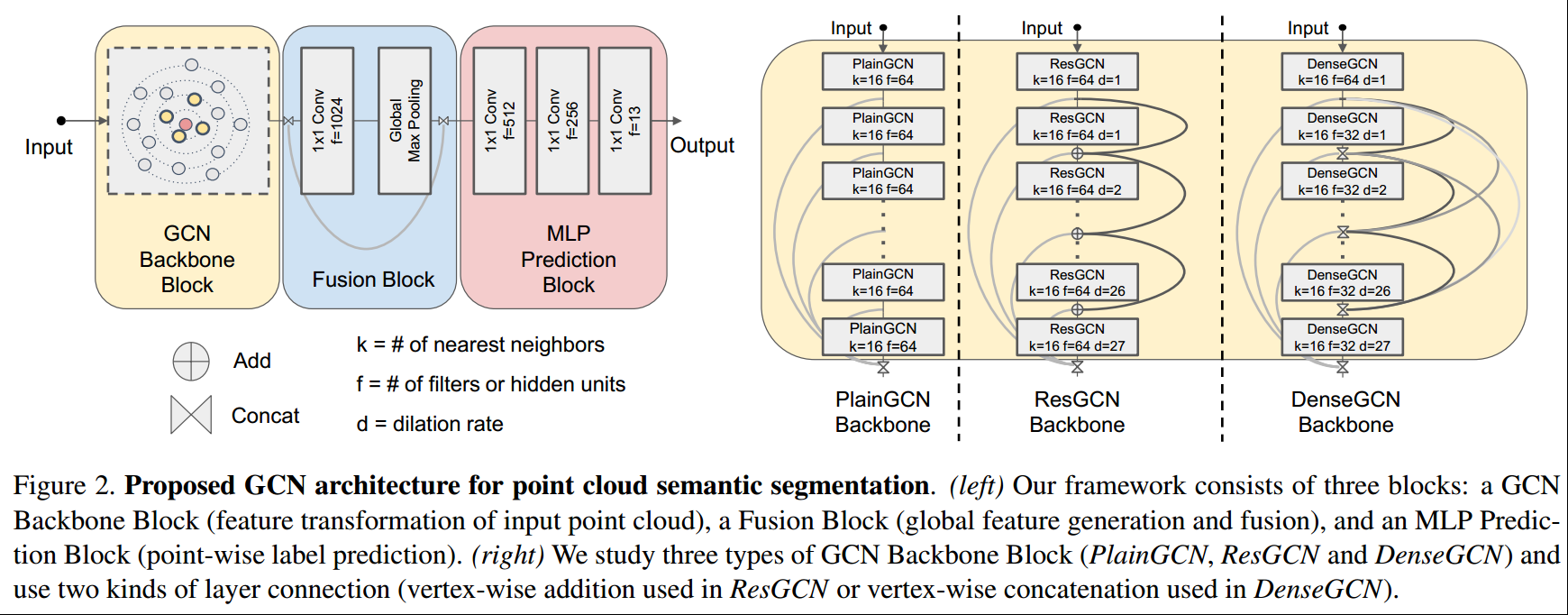
所有的网络架构都包含3个部分:GCN backbone block、fusion block和MLP prediction block,3种网络架构只在GCN backbone block上有连接模式的差别,但参数数量是一致的,因为这里使用的是图像,所以实现全连接都是使用1x1conv实现的。
GCN backbone block的输入维度都是4096个点,输出也是4096个点:
其dilation rate是随着深度增加而线性增加的;
对于PlainGCN,是堆叠了28个EdgeConv【42】,使用的是dynamic k-NN,每个和DGCNN【42】使用的类似;
对于ResGCN,是每个EdgeConv的输出和输入会加在一起再往下计算;
对于DenseGCN,是将之前所有EdgeConv的输出都concat到一起在往下计算的,可能为了保证参数的相同,除了第一层其他层的filters数量是前面的一半,变成了32(但实际上我进行了简单的计算,发现其参数也是比较多的);
注意到,所有GCN layers的输出都会最终被concat在一起输出,不管使用的是哪个网络结构;
Fusion block【27,42】是用来将global信息和multi-scale local信息进行融合的:
首先将GCN backbone block的输出经过一个1x1 conv,映射到1024的维度,然后在整个图上将4096个batch size x 1024的矩阵进行global max-pooling,得到一个batch size x 1024的矩阵表示global information;
将这个信息concat到GCN backbone block的输出中去,就是在每个节点的特征矩阵后面再concat这个batch size x 1024矩阵;
MLP prediction是3层,依次得到512、256、13的输出维度,给每个节点进行分类
其他:
- 使用Tensorflow,两张Tesla V100,每张batch size是8;
- Adam,lr=0.001,每经过300000 steps学习率降低50%;
- 每一层使用BN,在MLP的第二层使用0.3的dropout;
- 对于dilated k-NN,其\(\epsilon=0.2\);
- 没有用任何的数据增强和预训练技术,端对端的进行训练;
PyG中已经有此模型的实现。
结果
进行了不同参数的探索,其结果在tab1中,因为ResGCN-28训练比较快,所以各种超参数的探索是基于此做的,但应该DenseGCN也是符合的。
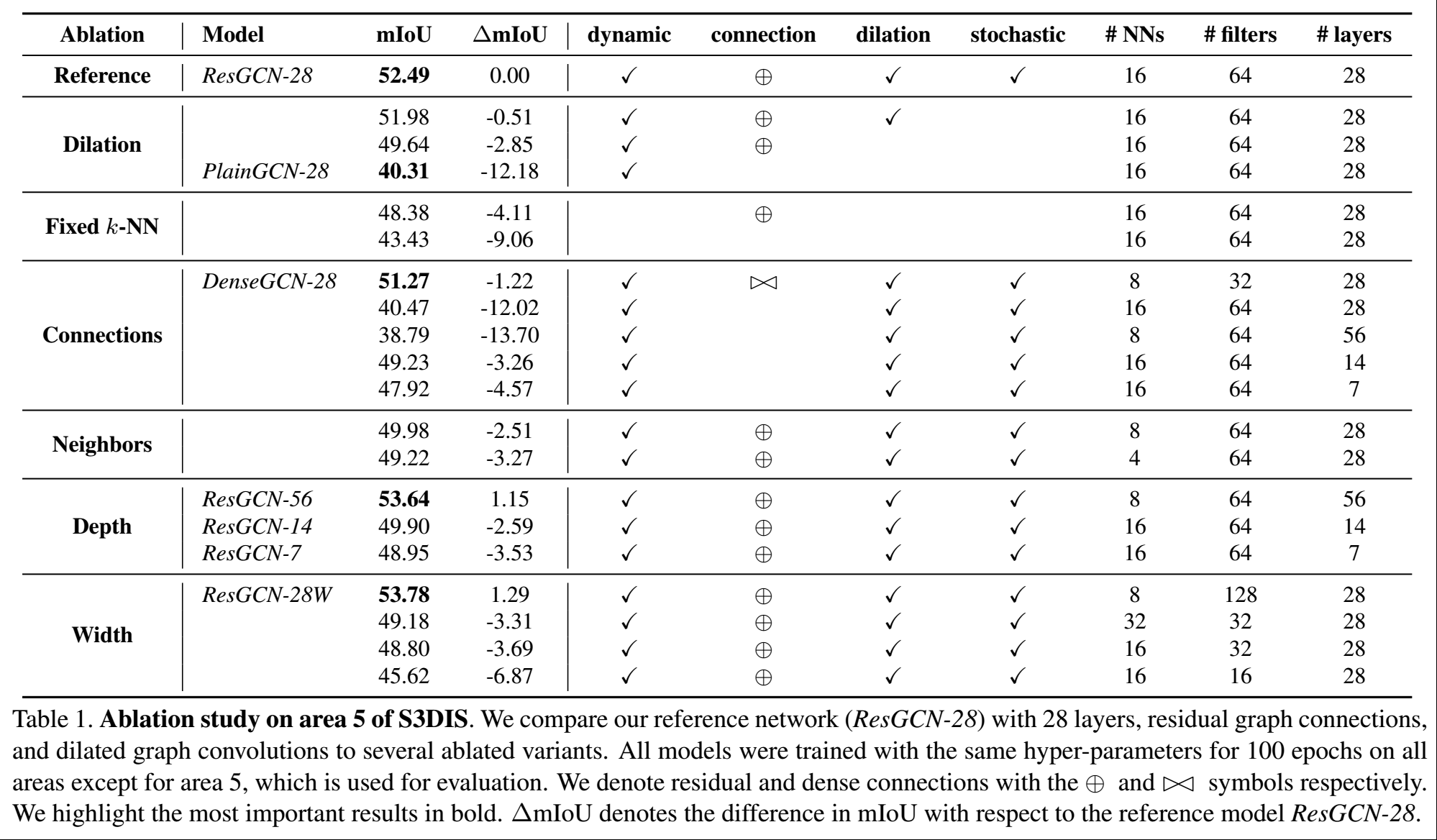
residual link
从tab1中可以看出,不管是什么样的配置,只要去掉了残差连接,那么都会导致mIoU的下降,和reference值相差一个残差连接的下降了12.02的mIoU。
dilation
使用dilation会导致IoU的提高(row 2 vs 3),得到了2.85的提升;
实际性的实施并没有很大的提升(row1 vs 2),0.51;
如果没有残差连接或dense连接,dilation反而会导致性能的降低(row 1 vs 8),这解释为梯度的不正确所导致的。
Dynamic k-NN
固定住边,而且没有使用dilation,会有4.11的下降(row1 vs 5);
如果进一步去掉残差连接,其效果下降的更大了。
dense link
为了适应内存,所以使用了8邻居、32filters的设置,发现了ResGCN效果差不多;
但因为效率的问题,还是使用ResGCN更好。
other
- 邻居越多确实可以提高性能;
- 深度增加可以提高预测性能;
- 这里的宽度是filters的大小,宽度增加可以提升性能;
定性结果见fig4,显然ResGCN-28和DenseGCN-28要好于PlainGCN-28。

另外,也和state-of-the-art进行了比较,如下:
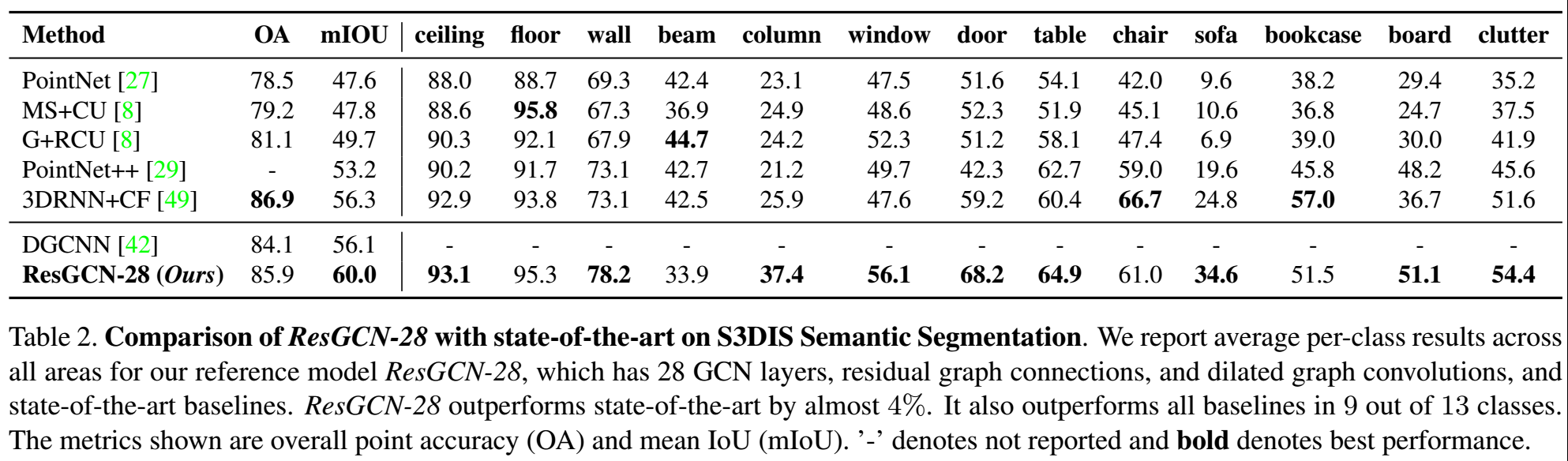
这里使用死的是EdgeConv,后面本研究又对其他4种GCN结构(GCN、SAGE、GIN、MRGCN)进行了相同的处理,即通过res、dynamic k-NN graph来对他们进行加深,发现确实都提示他了其效果,相关内容见文章的附录。
Conclusion
即便使用比较小的邻居数量,但因为使用了dilated技术,也能够有比较高的表现;
还训练了ResGCN-151 80个epoch,其只是用了3个邻居,但得到了和ResGCN-28和ResGCN-56相似的结论;
除了能够解决了over-smoothing的问题,网络加深、加宽还可以提升性能;
未来可能更多的将CNN领域的一些成功技术转移到GCN领域,比如deformable conv【6】、比如feature pyramid architectures【52】等其他架构,也可以考虑使用其他的距离来度量邻居,在每一层使用不同数量的邻居,更好的dilation策略【4,41】等;
对于点云语义分割的特定任务,使用1m x 1m的处理数据的形式并不是最佳的,应该探索更合适的形式。
Questions
- 这里根据resnet的思想,一般经过多层的映射后才实行残差连接的,这里只进行一层效果好吗?
- 这里对于GCN block的详细配置没有说明,只是指出其和DCGCN类似,这必须通过看代码来知道了。



